Report Memphis.dev Cloud Performance And Load Report
Comparisons
Apache Kafka vs Message Queue

 Contents
Contents
Apache Kafka (A message broker) and message queues are used for different purposes. Although they both provide a mechanism for exchanging messages asynchronously between applications. They can be seen as similar. However, they both have different purposes. This post compares Kafka vs message queues to help you understand their key differences and alternatives to consider achieving application decoupling while exchanging data.
What is a message queue?
A message queue is an asynchronous communication architecture that allows inter-microservices applications and systems to send tasks via a queue as messages are pending to be processed.
The producer creates messages; a message queue accepts stores and makes these messages available so that the respective consumers can process them. It follows a very straightforward pattern. A message created by a producer contains a payload of the actual data being sent or received. A queue stores and manages the flow of these messages. Any consumer the producer intends to communicate with can pick these messages from the queue and process them accordingly.
A good example of a message queue communication can be identified between a web app and a backend server. In this case, the web app sends a message containing a user request to the queue. The server then processes the request and sends a response back to the app via the message queue. Messages are produced by the producer, received by the consumer via a queue, and then removed from the queue once the communication exchange is processed.
What is Apache Kafka?
Apache Kafka is an open-source, distributed streaming platform. Just like a message queue, it provides you with the capability of sending and receiving data from one application to another application, as well as storage and processing capabilities.
Kafka provides a distributed, partitioned, replicated commit log service architecture. It provides the functionality of a messaging queue but with a broker pattern of many producers to many consumers at once.
Is Kafka a message queue?
You can think of Kafka as a message queuing system with a few tweaks. Kafka is able to provide a high availability and fault tolerance, low-latency message processing approach just like a traditional message queue. However, it brings additional possibilities that a typical message queuing system can fail to provide.
Message queues provide a basic messaging model for background task processing and simple application integration. They provide primary message storage and processing capabilities. However, they don’t have the advanced features and scalability of Kafka. Message queues are limited because messages are removed from the queue after a single consumer processes them. This technique is incompatible when creating highly scalable applications.
Kafka addresses the weaknesses of traditional message queues strategies providing fault-tolerant, high-throughput stream processing. This way, Kafka cannot fully be categorized as the conventional message queue. Kafka is a distributed messaging platform that includes message queue and publish-subscribe (“pub-sub”) systems components. It provides publish-subscribe patterns that have the ability to scale horizontally across multiple servers while retaining the ability to replay messages.
This makes it a very good choice for patterns that require real-time processing and high scalability, such as streaming and big data platforms.
Save time and get both!
Instead of having two different tools, why not use a unified tool that serves both purposes?
Discover more

Comparing Kafka vs messaging queues
Let’s dive in and discuss the battle between queues and brokers. To understand their core difference, we will compare Kafka vs traditional messaging queues and explore the differences, trade-offs, and architectures.
Architecture difference
A messaging queue uses a straightforward architecture. It’s made up of three major components. The producer, queue, and consumer are as follows:
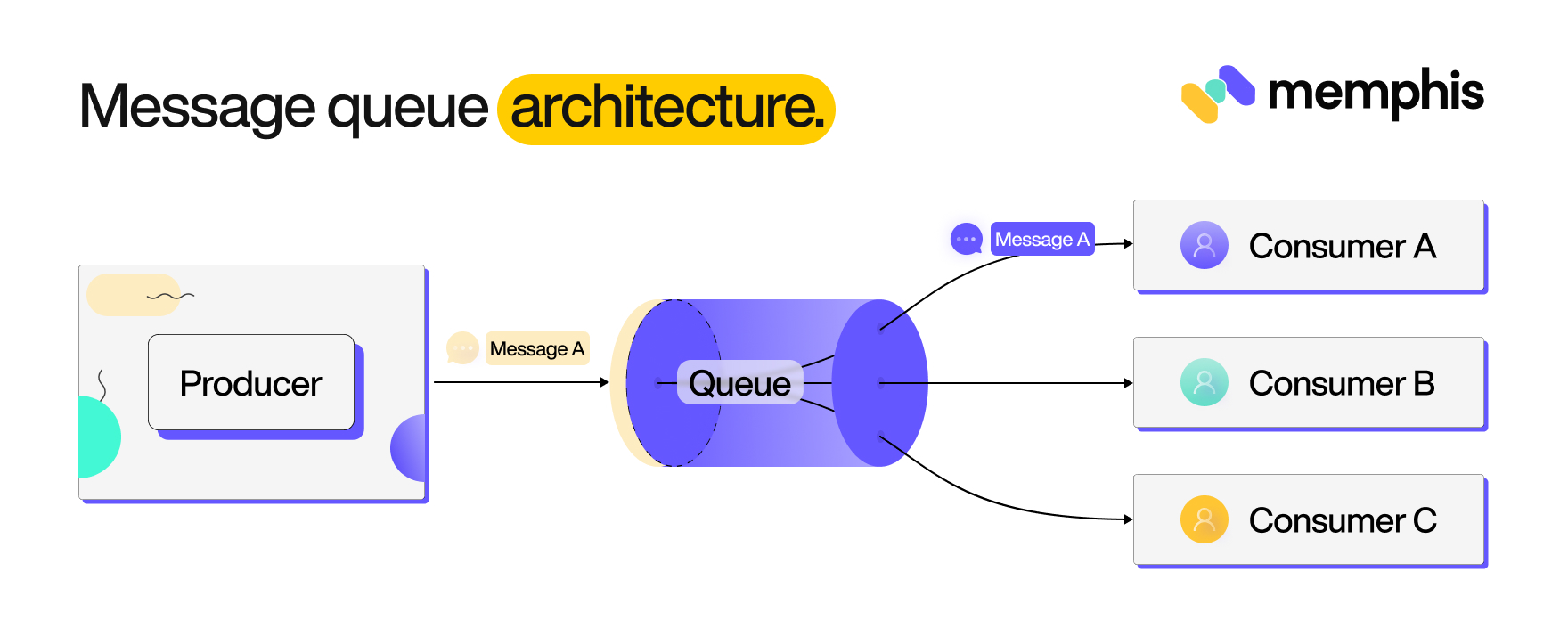
Kafka is a pub-sub based model. You have multiple data producers, and the same data is consumed by multiple applications or consumers. Message queues may fail to handle such data pipelines to match the throughput and scalability of enterprise messaging systems.
Like a message queue, Kafka has two parties: a producer (sends data) and a consumer (reads the data). Producer sends data to Kafka. Kafka will store data on its server; whenever consumers want to consume it, they can request it and pull it from Kafka.
This is where Kafka starts to get different from queues; whenever producer API creates a new message, it is split into Partitions and stored on disk in an ordered, immutable log called a topic which can persist forever. Kafka then distributed and replicated these topics in a cluster. A cluster can contain different servers (Brokers) to give Kafka the characteristics of being fault-tolerant and highly scalable to any workload.
The following is the above Kafka ecosystem representation in a nutshell:
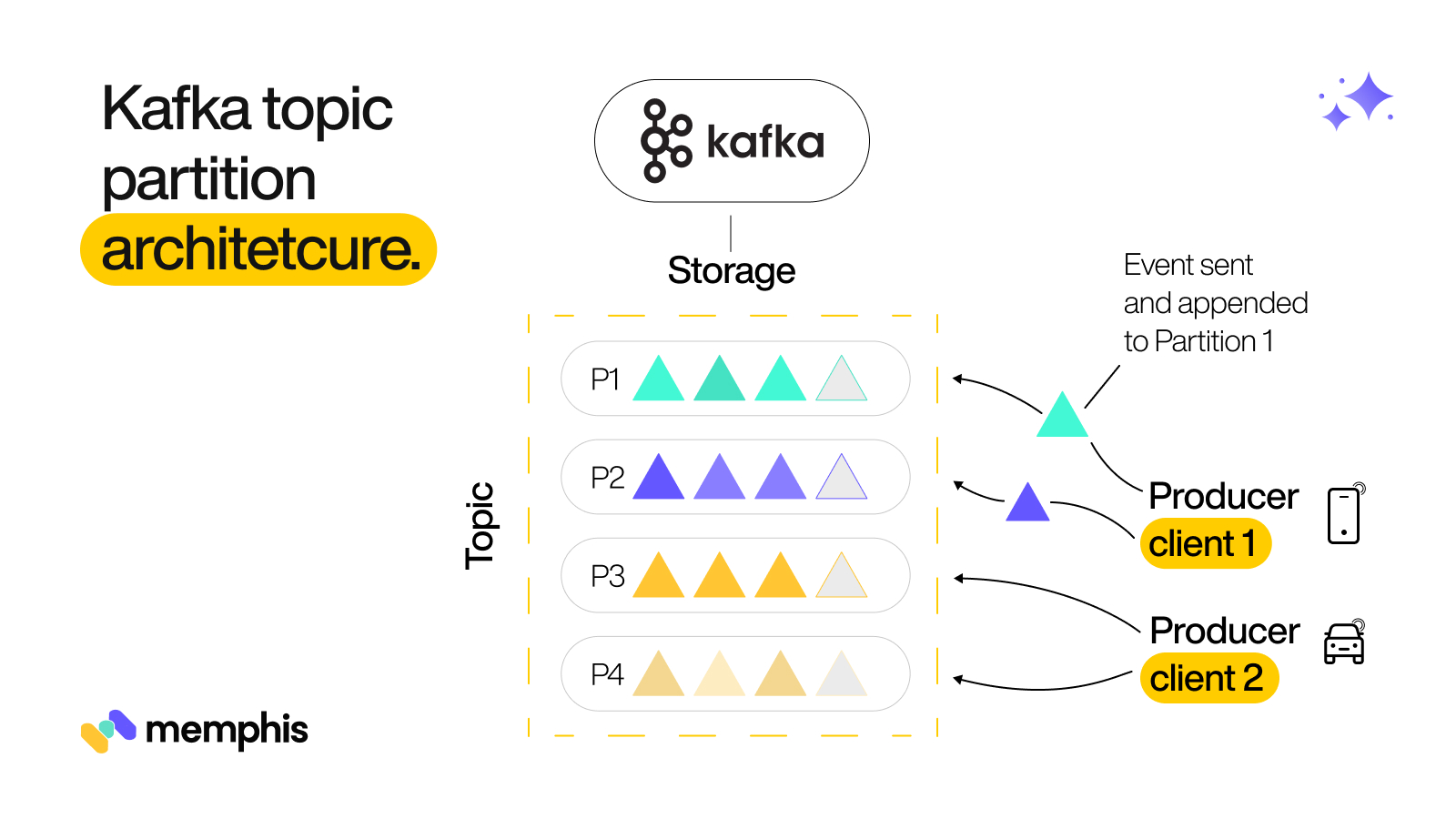
Based on its pub/sub model, consumers can subscribe to a topic and receive data sent by the producers to read the most recent message in the entire topic log. This way, consumers can listen to updates in real-time and act accordingly.
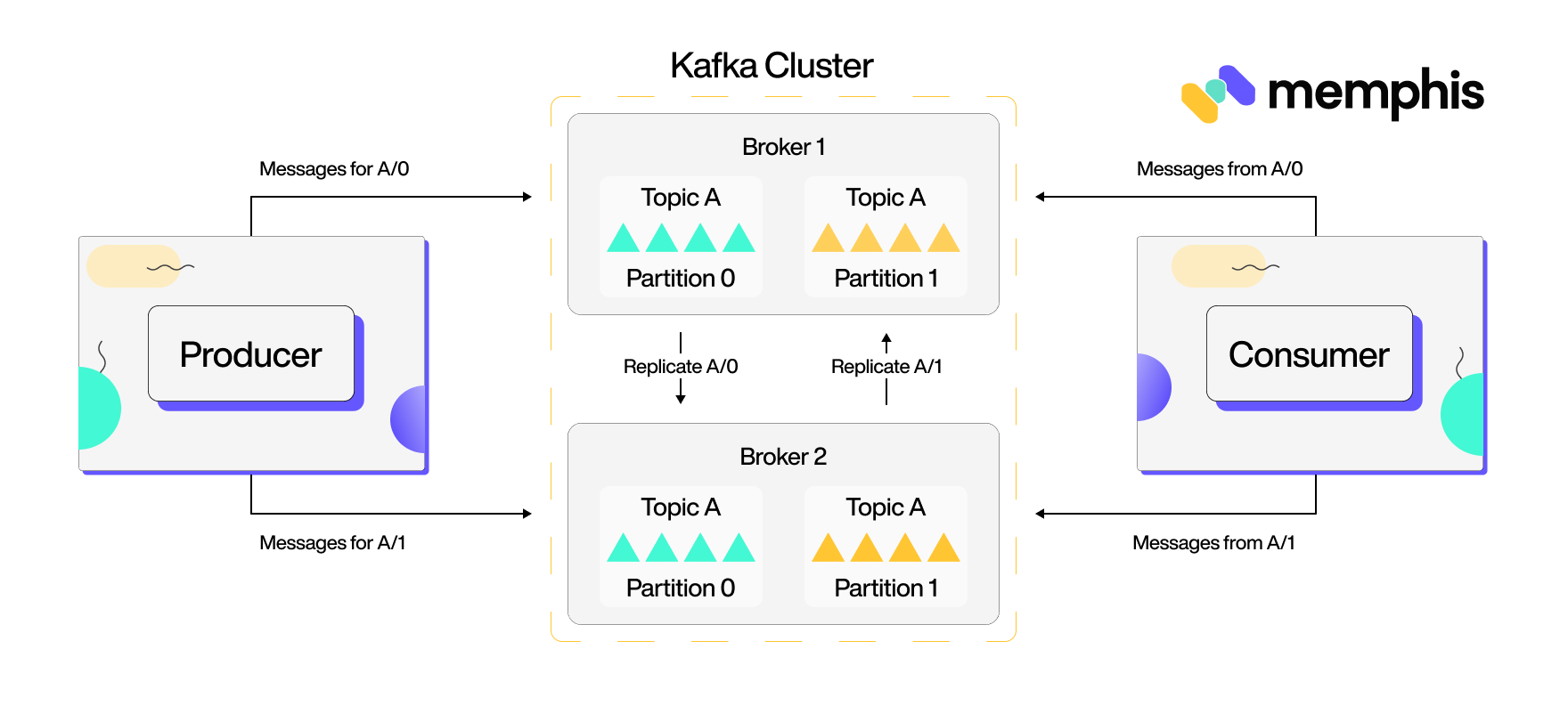
Behavior differences
A message queue enables subscribers to retrieve messages from the queue for processing. A subscriber can retrieve a single message or a batch of messages all at once. Queues often check if the message’s requested task was completed successfully. If so, the message is permanently removed from the queue. It has the following features:
- It uses a push or pull delivery model. Pulling means constantly querying the queue for new messages, while push ensures the consumer is notified when a communication is available.
- Queues process messages in the FIFO approach, a First-In-First-Out model.
- Each message (without duplicate tolerance) is delivered exactly once.
- Provide Dead-letter queues for retry and process messages that cannot be processed successfully.
At its core, Kafka provides the following features and twists to the traditional messaging queue:
- Its Scalability ensures that you have a few data producers generating a large dataset and distributing it to a large number of data consumers or that your application can scale out when needed.
- Performant and low latency with high-throughput capabilities for real-time data processing.
- Its replication and partitioning features provide robust fault tolerance and ensure your application and data work even in server failures.
- Ability to handle high-volume based data streams.
- Zero downtime ensures you upgrade and maintain your services without affecting the system’s availability.
- Kafka is open-source and is free to use.
Use cases
While message queues aren’t the right choice for real-time communication, queues can be used:
- Acts as a buffer to facilitate messaging queuing for bulk processing.
- Decoupling processing.
- A good choice for a single consumer microservice architecture.
Kafka its use cases such as:
- Stream processing using Kafka Streams APIs to process large volumes of data efficiently and scalable.
- Commit log for log records that capture all your application changes.
- Advanced messaging as a replacement for the traditional messaging queues.
- Metrics and log aggregation – You can collect metric monitoring data and logs for application observability.
- Website activity tracking for user activity tracking pipelines.






