Report Memphis.dev Cloud Performance And Load Report
Data Engineering
Batch Processing vs Stream Processing: Why Batch is dying and Streaming takes over

 Contents
Contents
In the digital age, data is the new currency and is being used everywhere. From social media to IoT devices, businesses are generating more data than ever before. With this data comes the challenge of processing it in a timely and efficient way. Companies all over the world are investing in technologies that can help them better process, analyze, and use the data they are collecting to better serve their customers and stay ahead of their competitors.
One of the most important decisions organizations make when it comes to data processing is whether to use stream processing. Instantaneous processing is quickly becoming the go-to option for many companies because of its ability to provide instantaneous insights and immediate actionable results. With the right instantaneous processing platform, companies can easily unlock the value of their data and use it to gain a competitive edge. This article will explore why instantaneous processing is taking over, including its advantages over sequential processing, such as its scalability, cost-effectiveness, and flexibility.
Let’s recap some of the basics first.
Data Processing
Information transformation is the process of converting raw data into meaningful and valuable insights. It encompasses a wide range of activities, including data collection, data cleansing, data integration, data analysis, and data visualization. This process plays a crucial role in various industries such as finance, healthcare, education, engineering, and business, supporting informed decision-making and analysis.
Information transformation can be categorized into two primary approaches: Manual Information Transformation and Automated Information Transformation.
Manual information transformation involves manual input, paper forms, hand calculations, and data entry into software programs. While this method can be slow and prone to errors, it remains valuable for managing substantial data volumes and complex tasks. On the other hand, automated information transformation is faster and more efficient, leveraging algorithms and software to automate data-handling tasks like sorting, filtering, and summarizing.
Information transformation can also be further classified into different types, including sequential processing and instantaneous processing, as well as multi-processing and time-sharing.
- Sequential Processing: This approach entails executing a series of predefined instructions or programs on a batch of data. It is commonly employed for tasks that demand processing substantial data volumes, such as data mining and data warehousing.
- Real-time Processing: Real-time processing involves continuous and immediate data stream analysis. It is typically applied in situations that require instant data analysis and responses to incoming data, like fraud detection and monitoring user activity.
- Stream Processing (Instantaneous Transformation): Stream data processing focuses on the continuous, instantaneous analysis of data streams. It is akin to instantaneous processing but often involves more complex operations and can handle large data volumes with minimal latency.
- Multi-Processing: Multi-processing involves multiple processors simultaneously working on separate tasks. It is frequently used to expedite the processing of large data volumes, as employing multiple processors enables tasks to be completed faster than on a single processor.
- Time-Sharing: Time-sharing enables multiple users to access the same computer or system simultaneously. Time-sharing systems offer greater efficiency and performance than sequential processing and are commonly used in applications such as online banking, e-commerce, and web hosting.
In summary, information transformation is a vital component of modern business and society. It plays a pivotal role in converting raw data into actionable insights that facilitate informed decision-making and drive business growth.
Let’s discuss stream and batch data processing in detail.
What is Stream Processing?
Stream processing is a kind of data processing that involves continuous, instantaneous analysis of data streams. It is a way of handling large doses of data that are generated by various sources, such as sensors, financial transactions, or social media feeds, instantaneously.
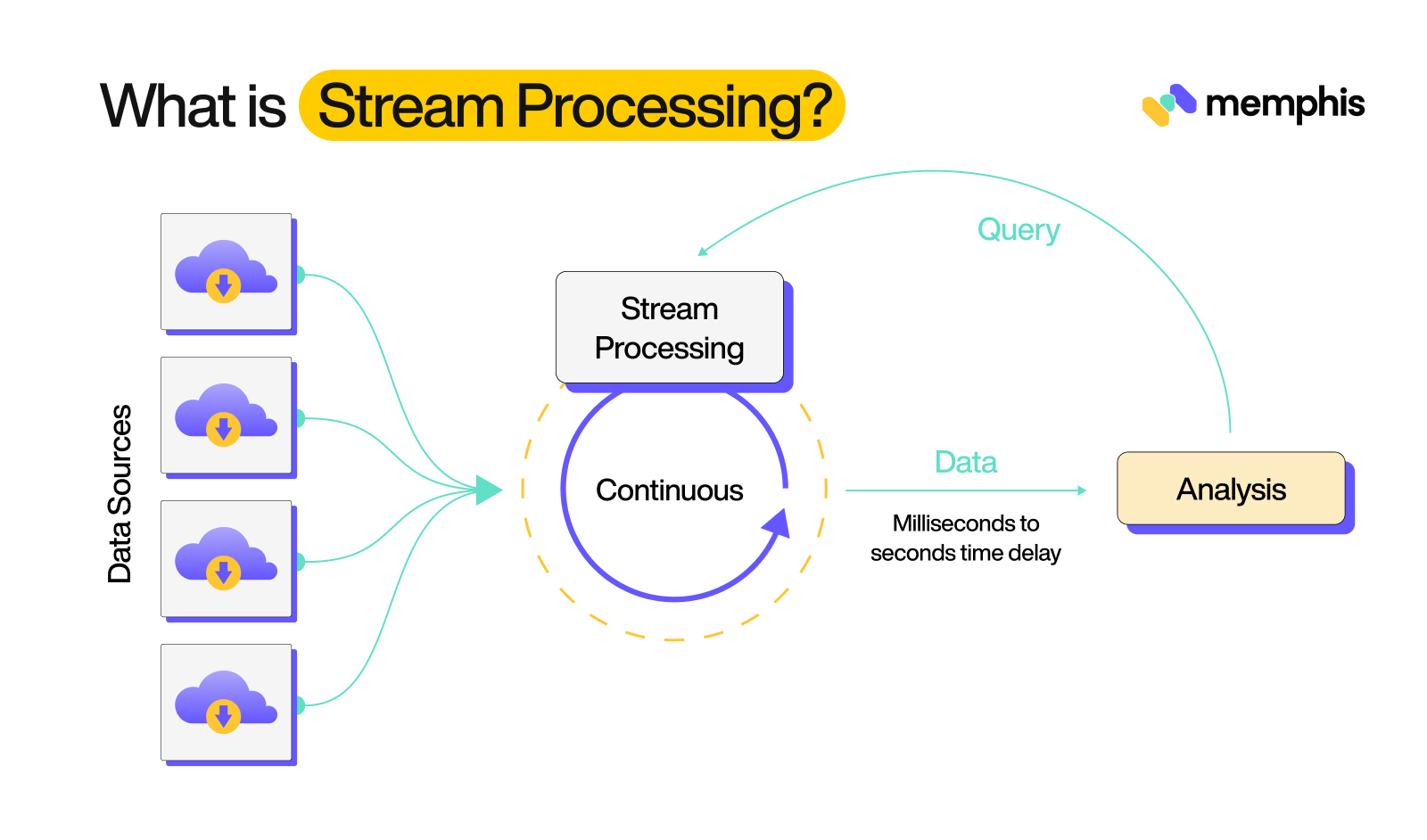
Advantages of Stream Processing
Real-Time Nature: One of the primary advantages of instantaneous processing is its instantaneous nature. Because data is handled as it is received, instantaneous processing allows for faster analysis and decision-making. This can be especially useful in applications where time is of the essence, such as in financial trading or emergency response.
Scalability: Another advantage of instantaneous processing is its scalability. Because instantaneous processing systems are designed to handle large portions of data instantaneously, they can easily scale to handle increases in data volume without compromising on performance. This makes them well-suited to applications that deal with significant doses of data, such as Internet of Things (IoT) applications or social media analysis.
Reduced Cost: Instantaneous processing also helps organizations save money by reducing costs associated with storing significant doses of data. Instantaneous processing systems can store only the data that is required for processing, eliminating the need to store and manage large datasets.
Security: Instantaneous processing is more secure than traditional sequential processing systems. Instantaneous processing systems use encryption techniques to ensure that data is kept secure and confidential. This helps organizations to ensure that their data remains safe and secure.
Challenges of Stream Processing
Overall, instantaneous processing is a powerful tool for handling large doses of data instantaneously, but it also comes with its own set of challenges.
One of the main challenges of instantaneous processing is ensuring the accuracy and consistency of the data. Because instantaneous processing involves continuous analysis of data instantaneously, any errors or inconsistencies in the data can quickly propagate throughout the system, leading to incorrect results. This can be particularly problematic in complex systems with many different data sources and can require careful design and management to ensure the quality of the data.
Another challenge of instantaneous processing is dealing with late or out-of-order data. In instantaneous processing, data is often generated by multiple sources, and it can arrive at different times or in a different order than expected. This can make it difficult to accurately process the data and can require the use of specialized techniques to handle such situations. For example, some instantaneous processing systems use techniques such as windowing or buffering to delay the processing of data until all necessary information is available or to reorder data if it arrives out of sequence.
A third challenge associated with instantaneous processing is maintaining the performance of the system. Because instantaneous processing involves continuous analysis of data, it can put a heavy load on the underlying infrastructure, which can impact the overall performance of the system. This can be particularly problematic in systems with high volumes of data, or with complex data handling pipelines. To address this challenge, instantaneous processing systems often use techniques such as parallelism, load balancing, and data partitioning to distribute the workload across multiple machines and improve the overall performance of the system.
The challenges stated above can be addressed through careful design and management of the system, as well as the use of specialized techniques to ensure the accuracy and performance of the data handling pipeline.
Use Cases
Instantaneous processing can be used in many different use cases and can be applied to a variety of industries, including finance, retail, healthcare, telecommunications, and IoT.
Finance: Instantaneous processing can be used to analyze market data instantaneously and detect fraud. By analyzing customer transactions and patterns, banks can quickly identify suspicious activity and alert authorities. This helps reduce the potential losses caused by fraudulent activities.
Retail: Stream processing can be used to provide customers with personalized offers and recommendations. By analyzing customer data instantaneously, retailers can create targeted campaigns that are tailored to each individual customer’s preferences. This allows them to offer more relevant products and services, which can lead to increased customer satisfaction and loyalty.
Health Care: Instantaneous processing can be used to monitor patient health instantaneously. By collecting data from various medical devices and sensors, healthcare providers can quickly identify any changes in a patient’s health status. This can help them detect and treat conditions before they become serious and costly.
Telecommunication: Real time processing can be used to monitor network performance instantaneously. By analyzing data from various telecommunication networks, service providers can quickly identify any issues or outages and take corrective action. This helps them maintain a high level of service quality and provide reliable connections to their customers.
Internet of Things (IoT): Stream processing can also be used to collect and analyze data from connected devices. This can help organizations gain valuable insights into how their devices are performing and make informed decisions about how to optimize their operations.
What is Batch Data Processing?
Batch (sequential) data handling is a method of executing a series of tasks in a predetermined sequence. It involves dividing a significant amount of data into smaller, more manageable units called sequences, which are processed independently and in parallel. In sequential processing, a group of transactions or data is collected over a period of time and then processed all at once, typically overnight or during a maintenance window. Sequential processing is often used in large-scale computing systems and data-handling applications, such as payroll, invoicing, and inventory management.
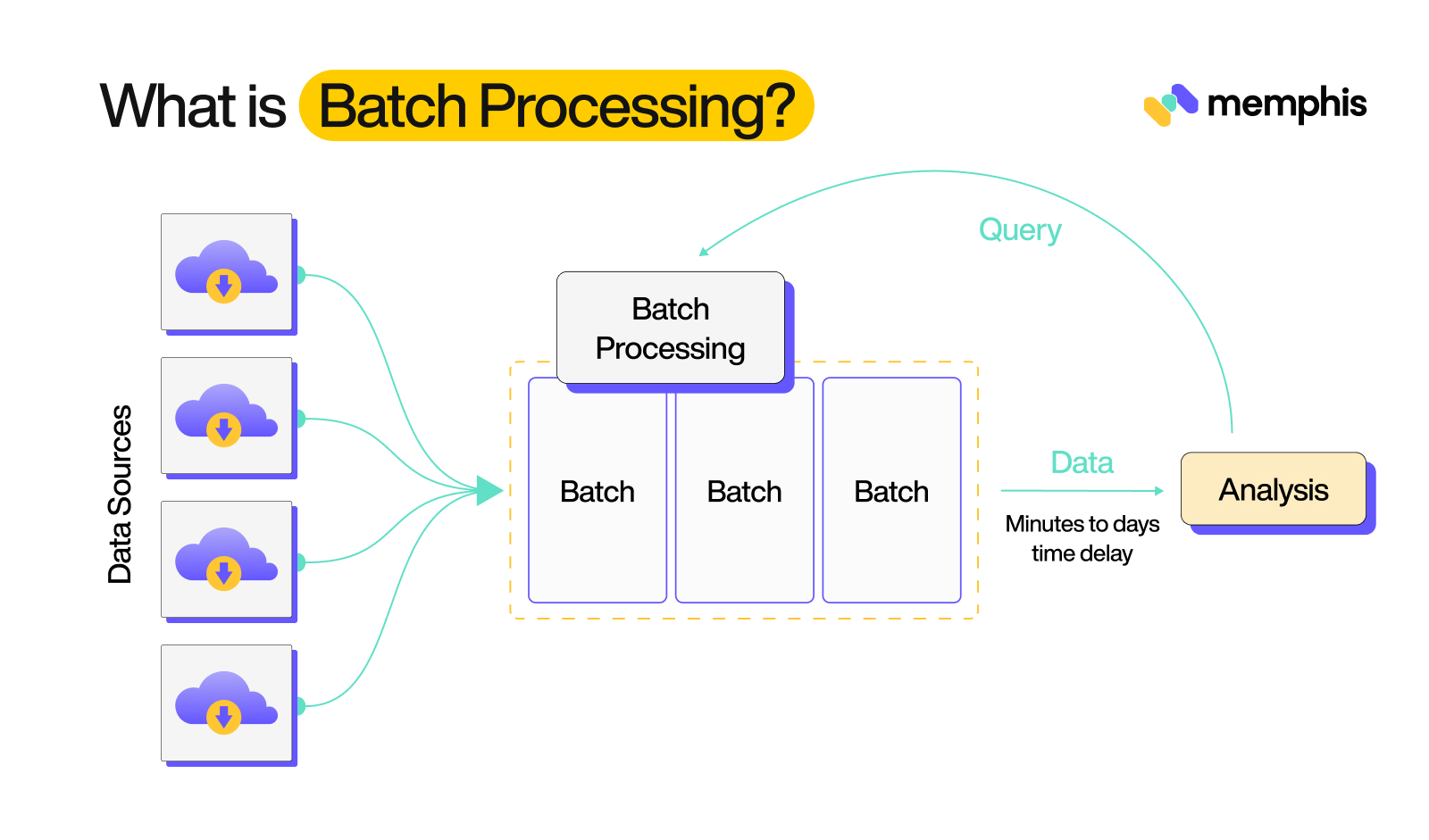
Advantages of Batch Processing
There are several advantages to using batch processing:
Improved efficiency and speed: Batch processing allows for the concurrent execution of multiple jobs, which can significantly improve the speed and efficiency of processing large amounts of data. By processing multiple transactions or data sets at once, sequential processing can reduce the amount of time it takes to complete a task, allowing organizations to complete more work in less time.
Reduced costs: Sequential data handling can also help to reduce costs by reducing the need for manual intervention and labor. By automating repetitive tasks, organizations can reduce the amount of time and resources that are required to complete a task, leading to cost savings.
Increased accuracy: Batch processing can help to increase the accuracy of data handling by ensuring that all transactions are processed consistently, according to predefined rules and procedures. This can help to reduce the potential for errors and inconsistencies, leading to more accurate and reliable results.
Enhanced security: Sequential processing can also help to improve the security of data handling by limiting access to sensitive data to authorized personnel only. By controlling access to data and processing it in a secure environment, organizations can help to prevent unauthorized access and protect against potential security threats.
Improved scalability: Sequential data handling is highly scalable, meaning that it can be easily adapted to handle increased volumes of data without a significant impact on performance. This allows organizations to easily and efficiently process significant doses of data as their needs evolve, without the need for additional resources or infrastructure.
Challenges of Batch Processing
There are also some challenges associated with batch (sequential) processing.
One of the main challenges is the need for careful planning and coordination. Since sequential processing is executed in a predetermined sequence, it is important to carefully plan and coordinate the execution of tasks to ensure that they are completed in the correct order.
Another challenge of batch processing is that it can be time-consuming. Since data is collected and processed in large quantities, it can take a significant amount of time to complete a batch. This can be especially problematic for businesses that need to handle data instantaneously, as sequential processing may not be fast enough to keep up with the demands of the business.
Batch processing can also be more complex to implement and maintain, as it requires the development and management of batch schedules and processes. This can require additional resources and expertise, which can be a challenge for some organizations.
Another challenge of batch processing is the limited visibility it provides into the status of individual transactions or data items. With batch processing, it is often difficult to see the status of a particular transaction or data item within the batch, which can make it challenging to identify and address any issues that may arise.
Batch processing can also present challenges when it comes to maintaining data integrity. If a batch fails, it can be difficult to determine which data items were processed and which were not, which can lead to data loss or errors.
In addition, batch processing can be error-prone. Since data is catered in large quantities, it can be difficult to catch and correct errors in the batch. This can lead to inaccurate or incomplete results, which can be damaging to a business.
Use Cases:
Data analytics: Batch processing is used in data analytics to process large portions of data and generate insights or reports. For example, a company might use sequential processing to analyze customer data and generate reports on customer behavior or preferences.
ETL (extract, transform, load) processes: Batch processing is often used in ETL (extract, transform, load) processes to extract data from various sources, transform it into a format suitable for analysis or reporting, and load it into a data warehouse or other system.
Inventory Management: Sequential processing is also used in inventory management systems to process orders, track inventory levels, and generate reports. By processing data in sequences, it is possible to more efficiently manage and track inventory levels.
Financial transactions: Batch processing is commonly used in the financial industry to process large numbers of transactions, such as credit card transactions or stock trades. For example, a bank might use Sequential processing to process transactions from multiple branches or ATM machines, and then update customer accounts accordingly.
Online services: Sequential processing is also used in the development of online services, such as web applications or mobile apps. For example, a social media platform might use Sequential processing to process large portions of data in order to generate recommendations for users or to generate reports on user behavior.
Batch Processing vs Stream Processing: An Overview
Batch Processing vs Stream Processing: Hardware
When it comes to hardware, there are some key differences between sequential processing and instantaneous processing. Sequential data handling typically requires more powerful hardware, as it needs to be able to handle large quantities of data all at once. This can include powerful servers, high-capacity storage systems, and other specialized hardware.
On the other hand, instantaneous processing typically requires less powerful hardware. Since data is processed instantaneously, it does not need to be stored for later processing. This means that instantaneous processing systems can be more lightweight and can use less powerful hardware.
Overall, the type of hardware needed for batch processing and instantaneous processing depends on the specific requirements of the system and the quantities of data being processed.
Batch Processing vs Stream Processing: Performance
When it comes to performance, batch (sequential) data handling is generally less efficient than instantaneous processing. This is because sequential handling requires data to be collected and stored before it can be acted upon, which can consume a significant amount of time and resources. In contrast, instantaneous processing allows data to be acted upon as it is generated, which can save time and improve efficiency.
Additionally, instantaneous processing can manage large volumes of data with minimal latency. This is because instantaneous processing systems are designed to handle data in small increments as it is generated, rather than waiting for a large set of data to accumulate before taking action. This enables instantaneous processing systems to swiftly and efficiently work with data, without the need for extensive storage or costly hardware.
Batch Processing vs Stream Processing: Data Set
One of the main differences between batch processing and instantaneous processing is the type of data they are designed to handle. Sequential processing is typically used for data sets that are large and static, such as historical records or logs. In contrast, stream processing is typically used for data sets that are large but constantly changing, such as real-time sensor data.
Another important difference between batch processing and stream processing is the way they handle data. Sequential processing systems typically operate on data that is stored in a database or file system. On the other hand, stream processing systems operate on data that is generated in real-time or near-real-time.
Batch Processing vs Stream Processing: Analysis
One more area where these two data handling methods differ is the type of analysis they are designed to perform. Sequential processing systems are designed to perform complex, data-intensive analysis, such as machine learning and predictive modeling.
While, stream processing systems are suitable for performing simple, low-latency analyses, such as filtering and aggregation because it is designed for data handling in small chunks, which limits their ability to perform complex analysis.
Batch Processing vs Stream Processing: Platforms
There are several platforms available for both sequential processing and stream processing, each with its own unique features and capabilities.
Some of the most popular platforms for sequential processing include:
Apache Hadoop and Apache Spark, which are open-source distributed computing platforms that are widely used for big data processing and analysis.
For stream processing, some popular platforms include:
Apache Flink and Apache Storm, which are also open-source distributed computing platforms. These platforms are often used for applications such as monitoring systems and real-time analytics.
In addition to these open-source platforms, there are also several commercial platforms available for both sequential data handling and stream processing.
Some examples of commercial sequential processing platforms include Cloudera and MapR, which are distributed computing platforms that are designed for big data handling and analysis.
Let’s put some light on these commercial platforms!
Cloudera: Cloudera is a leading provider of enterprise data cloud solutions, including software and services for data engineering, data warehousing, machine learning, and analytics. Cloudera provides an enterprise data platform to customers of all sizes, enabling them to store, process, and analyze their data quickly, reliably, and securely. Cloudera also offers an array of professional services, such as consulting and training, to help customers get the most out of their data.
MapR: MapR is a distributed data platform for big data applications that provide fast and reliable access to data. It combines an optimized version of the Apache Hadoop open-source software with enterprise-grade features such as high availability, disaster recovery, and global replication. MapR also provides NoSQL databases, streaming analytics, and machine learning capabilities.
For stream processing, some popular commercial platforms include Confluent, Memphis, and Databricks, which are also distributed computing platforms. These platforms are often used for applications such as fraud detection and real-time recommendation engines.
Confluent: Confluent is an enterprise streaming platform built on Apache Kafka. It provides a range of services to support the development, deployment, and management of streaming data pipelines. It includes features such as real-time data integration, real time processing, and analytics. It also enables organizations to build mission-critical streaming applications.
Memphis: Memphis.dev is an open-source, real-time data processing platform
that provides end-to-end support for in-app streaming use cases using Memphis distributed message broker. Memphis’ platform requires zero ops, enables rapid development, and extreme cost reduction, eliminates coding barriers, and saves a great amount of dev time for data-oriented developers and data engineers.
Databricks: Databricks is a cloud-based platform for data engineering, machine learning, and analytics. It provides an integrated environment for working with big data that simplifies the process of managing and analyzing large datasets. It allows users to easily create data pipelines and complex analytics applications and supports popular open-source libraries such as Apache Spark, MLlib, and TensorFlow.
Overall, the choice of platform for batch processing or stream processing depends on the specific requirements of the application. Open-source platforms are often a good choice for applications that require flexibility and customization, while commercial platforms may be more suitable for applications that require support and scalability.
Why Batch is dying and Streaming Takes over?
There are several reasons why streaming has become more popular and why sequential processing may be declining in popularity.
One reason is the increasing demand for instantaneous processing. In today’s fast-paced world, many organizations require the ability to handle data instantaneously in order to respond to changing conditions and make timely decisions.
Another reason is the increasing availability of streaming technologies and tools. In the past, streaming was more difficult and expensive to implement, but today there is a wide range of tools and technologies available that make it easier and more cost-effective to implement streaming solutions. Also, with streaming it is possible to track the processing of data in real-time, which can be beneficial for debugging and monitoring purposes.
Conclusion
This blog post walks through the basics of stream and batch processing, lists some of the advantages and challenges associated with these data handling methods, and then compares them in terms of performance, data sets, analysis, hardware, and some other features.





