Report Memphis.dev Cloud Performance And Load Report
Data Engineering
Design Considerations for Cloud-Native Data Systems

 Contents
Contents
When it comes to designing a cloud-native data system, there’s no particular hosting infrastructure, programming language, or design pattern that you should use. Cloud-native systems are available in various sizes and shapes. However, it is true that most of them follow the same cloud native design principles. Let’s take a look at the cloud native architecture, the design principles you should keep in mind, and the features that make up a good cloud-native platform.
Cloud native architecture
A cloud native architecture is essentially a design pattern for apps built for the cloud. While there’s no specific way of implementing this kind of architecture or a pre-defined cloud native design, the most common approach is to break up the application into a number of microservices and let each microservice handle a different kind of function. Each microservice is then maintained by a small team and is typically deployed as a container.
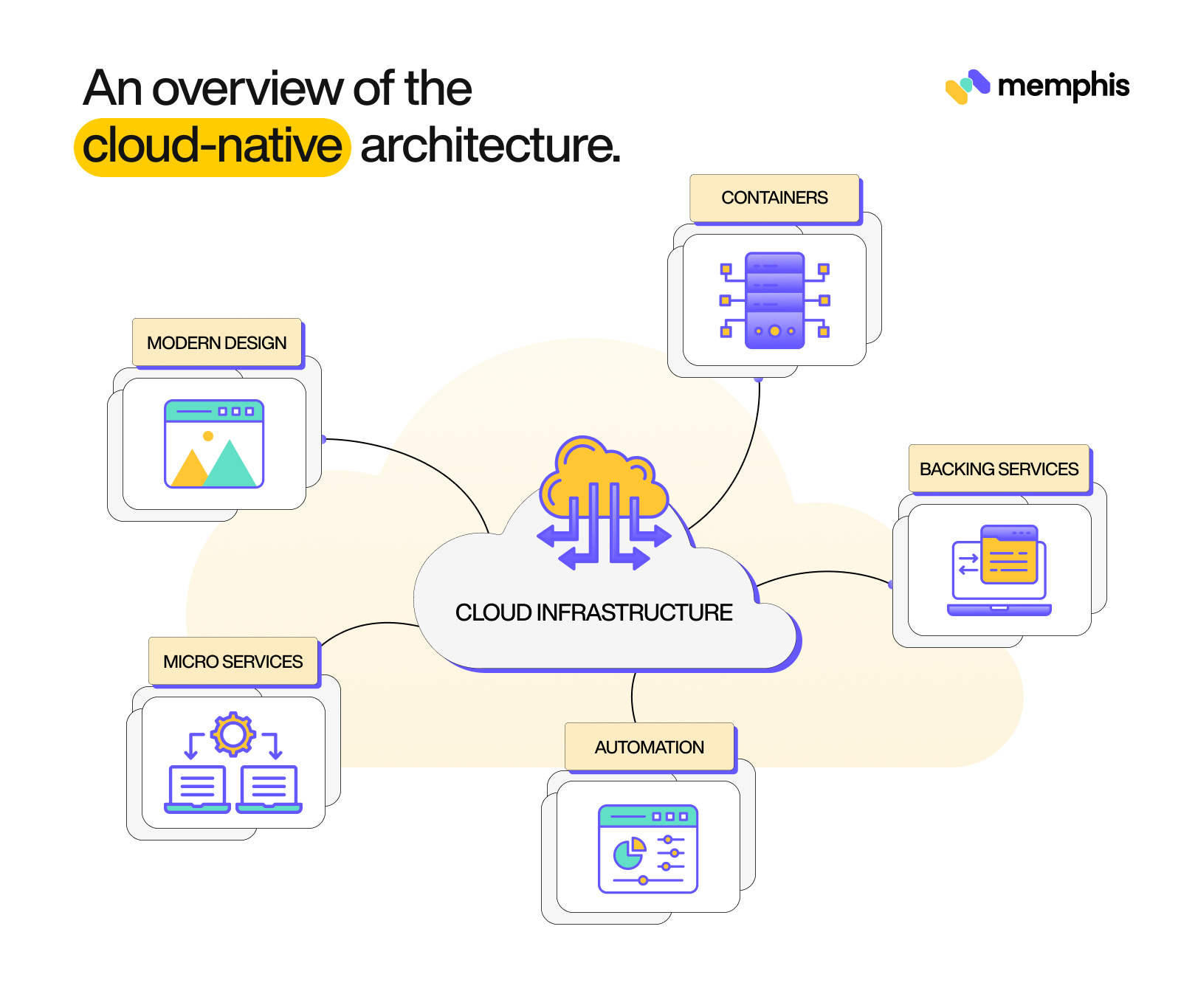
An overview of the cloud-native architecture (Source)
Let’s take a closer look at the architecture.
Embrace microservices
Cloud native design and development depends on a loosely coupled architecture, where different parts of the applications are developed, operated, and deployed independently. This is usually implemented using microservices.
It’s safe to say that microservices form the foundation of cloud-native systems, and you can really benefit from them by using containers that allow you to compress the runtime environment and its libraries, binaries, and dependencies into a logical and easily manageable unit. As a result, application services can be stored, duplicated, transported, and used as needed.
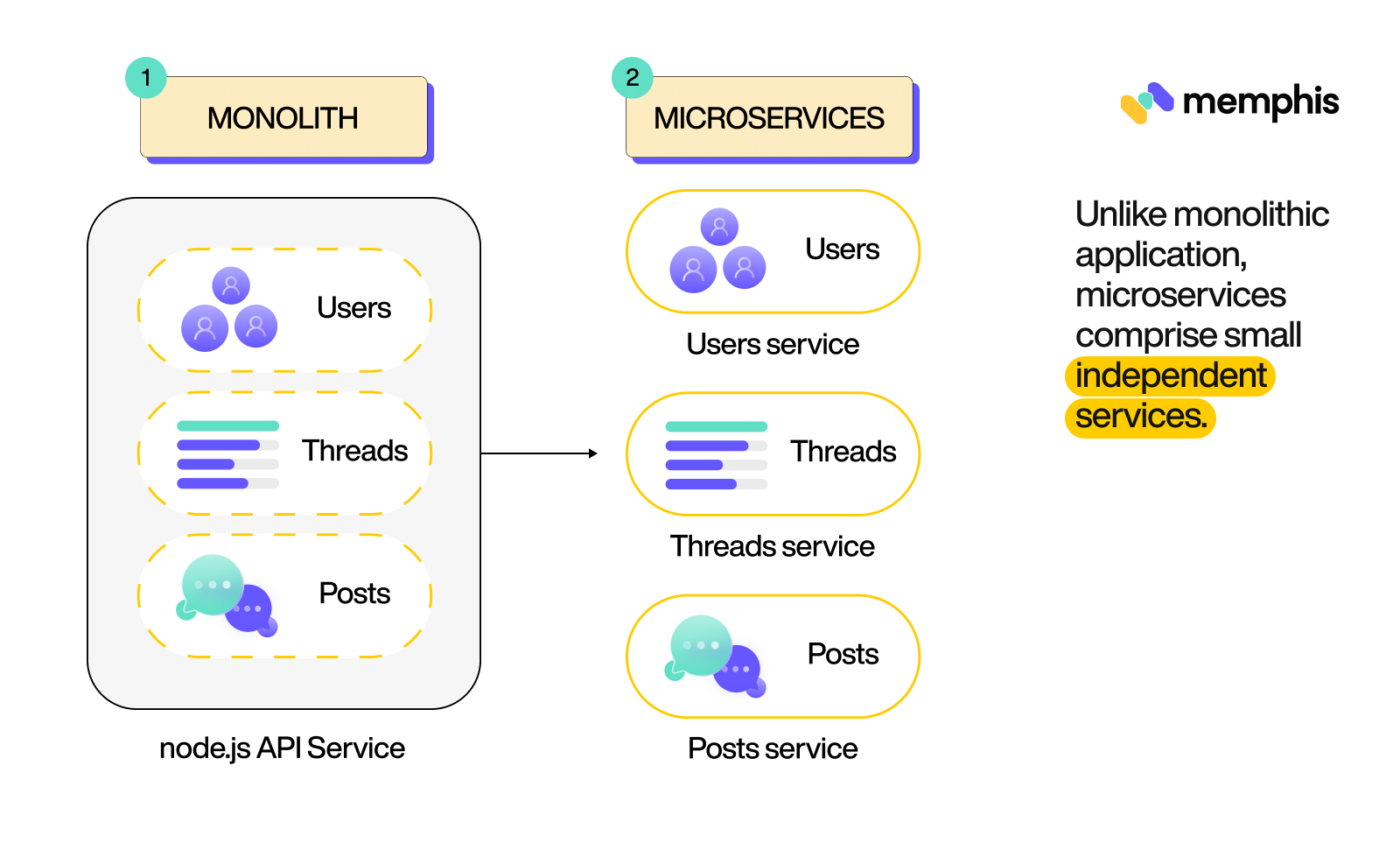
Unlike monolithic application, microservices comprise small independent services (Source)
The use of microservices (or loosely coupled architecture) is important for cloud computing for a number of reasons. For instance, it promotes simplicity, scalability, and resilience. Let’s take a closer look at how that’s possible.
With this architecture, you can break down complex applications into small independent parts, making the app development cycle simple and easier to manage. Not to mention, separating the app configuration and base code also makes developing and maintaining the app easier. Along the same lines, keeping the core application separate from the backing services allows the codebase to evolve and expand at its own pace.
Plus, it’s easier (and also faster) to scale up or down individual parts of one application instead of a whole monolithic app. Similarly, updating the app is easier since you have to update just the part (or microservice) that needs to be changed instead of deploying a new, updated version of the whole app again.
Embracing microservices also adds resilience and makes the app more reliable. If one component in a microservices architecture fails, the whole application won’t crash. It also promotes IaC (Infrastructure as Code) which, in turn, paves the way for automated deployment (which we’ll get to in just a bit). And finally, the microservice architecture involves the use of stateless processes and components via APIs, which isolates each microservice from others, leading to better security and efficiency.
To make sure that your application follows the loosely coupled architecture, you need to avoid making tightly coupled dependencies between the different parts. For instance, two microservices shouldn’t depend on the same database. If they do, you won’t be able to update and operate them independently.
Everything as Code
While it’s important to use microservices to benefit from modern applications, it’s also important to adopt automation practices. The purpose of this is to optimize the app development process and benefit both developers and users. For this, the ultimate goal is to achieve EaC – Everything as Code. Consider EaC as a step ahead of IaC, which comprises the app code base, infrastructure, and platform.
There are numerous benefits of this approach in terms of both hardware and software. For instance, it helps to implement version control at various levels and improves interdepartmental collaboration. It also facilitates the modularity of different components and enhances security via timely updates that help prevent vulnerabilities.
One key aspect of cloud-native data systems is the ability to implement automation at different levels using CI/CD tools. By adopting DevOps and agile principles, you can enjoy a number of benefits such as lower operational costs, better security, more flexibility, scalability, and fast cycle development.
Security, in particular, is very important. Manual handling often leads to attacks on cloud-native platforms, but implementing the best security practices via automation can really improve security. Plus, SecDevOps in CI/CD allows you to perform security testing in the early stages of the SDLC so that you can deal with the vulnerabilities early on in the development phase.
API-first approach
Developers are usually focused on code-first development instead of API-first development, but the problem is this approach is not the best for developing modern apps. For a cloud-native data system, you should encourage your developers to adopt an API-first approach and build software on top of that. Doing so will help save a lot of time and effort when laying down the basis for modern, distributed apps.
As we mentioned earlier, cloud-native data systems should follow the microservice architecture, where the services of an app are separated, and each service is executed as an autonomous application. As a result, individual microservices rely on APIs to communicate and interact with each other.
Keeping in mind the popularity of microservice architecture and modern applications, the importance of APIs is clear. Plus, an API-first approach allows developers to reap all the benefits of the microservices pattern. Apps that follow an API-first approach can be considered an ecosystem of interlocking services, where calls from applications and calls made by a user interface are considered API consumers.
There are numerous advantages of this approach. For instance, it makes a system highly scalable and reduces the chances of failure. It also cuts down development costs, improves the development experience, and increases speed-to-market by speeding up the development process. And in addition to facilitating communication between the user and the app via APIs, it also facilitates the automation and communication of internal processes.
Cloud native design principles
Cloud-native apps typically follow the principles defined in the 12-factor app framework and are built around security, resilience (and availability), elasticity, and performance (which includes scalability). Let’s take a closer look at these cloud native design principles.
Scalability
The idea behind scalability is to make it possible to add extra capacity to both the application and related services to handle the increase in demand and load. In particular, each application tier, how it can be scaled, and how bottlenecks can be avoided should be considered when designing for scalability.
There are three key areas to consider in this context: capacity, load, and data.
In terms of capacity, think about whether you’ll need to scale individual layers and if you can do so without affecting the app’s availability. You also need to consider how quickly you’ll need to scale services, and if you can scale down the app outside of business hours without affecting operations.
When it comes to data, think about whether you can scale keeping in mind the constraints of your services like transaction throughput and database size. Figure out how you can partition data to further boost scalability while staying within your platform constraints. Similarly, you need to figure out how you can use your platform resources effectively and efficiently.
And in terms of load, you need to determine how you can improve design to avoid bottlenecks and how you can use asynchronous operations to help with load balancing at peak traffic times. You also need to explore how you use the different rate-leveling and load-balancing features provided by your chosen platform.
One way to ensure scalability is to create automated processes that can scale, repair, and deploy the system as and when needed. You can set up the system such that it generates meaningful logs (and thus events) that you can then use as hooks for different automated activities. The resulting system should be able to automatically provision infrastructure such as machine instances, build, test, and deploy different stages in the CI/CD pipeline, and handle dynamic scalability and health monitoring and backup.
Many believe that cloud-native systems should be stateless, but this is quite difficult to achieve in real-world applications. However, since managing states is difficult to do in distributed applications, it’s better to use stateless components wherever you can. This is because stateless components make it easier to load balance, scale, repair, and roll back.
Availability
Availability refers to the ability of the system to be useful for the consumer despite faults in the underlying OS, hardware or network dependencies, or the app itself. Important principles include performance, uptime, disaster recovery, and replication.
When it comes to performance, you need to define the acceptable levels of performance, how they can be measured, and the actions or events that should be triggered when the performance falls below the acceptable levels. You also need to determine the parts of the app most likely to cause issues, and if a queue-centric design or auto-scale can help with that. Plus, you need to figure out if making some parts of the cloud-native system asynchronous can help improve performance.
Uptime guarantee is also important to consider. In particular, you need to define the SLAs that a product should meet and if it’s possible for your chosen cloud service to meet them. Meanwhile, in terms of disaster recovery, you need to determine how you can rebuild the cloud-native system in case of failure and how much data you can afford to lose in such a scenario. You also need to determine how you’re going to handle backups and in-flight queues and messages in case of failure, and figure out where you’re going to store the VM images and if you have a backup for that.
And finally, in terms of replication, you need to identify the parts of the system that are at high risk of failure and the parts that will be impacted the most by failure. Also, determine whether you need data replication and how you can prevent the replication of corrupt data.
Security
Security in cloud-native data systems is quite a broad topic and involves quite a number of things. But most importantly, you need to figure out:
- The local jurisdiction and laws where the data is held, including the countries where metrics and failover data are held.
- How you can secure the link between the cloud and corporate network if you have a hybrid-cloud app.
- If there are any requirements that should be met for federated security.
- How to control access to cloud provider’s admin portal, handle password changes, and restrict access to databases.
- How you’ll deal with the vendor and OS security updates and patches.
Manageability
Manageability refers to the ability to understand the system’s performance and health and manage operations. In terms of the cloud, we need to consider two principles – deployment and monitoring.
When it comes to deployment, you need to ask yourself a few things. For instance, think about how you’re going to automate the deployment and how you can patch or redeploy without causing any disruptions to the live systems. Also, think about how you’ll check if a deployment was successful and how to roll back in case it was unsuccessful. Similarly, deployment also involves determining the number of environments you’ll need and how much storage and availability they require.
Meanwhile, when it comes to monitoring, you need to plan how you’ll monitor the app (are you going to use off-the-shelf services or develop one from scratch?) and where you’ll physically store the monitoring data. You also need to determine the amount of data your monitoring plan will produce and how you can access metrics logs. Similarly, ask yourself if you can afford to lose some of the logging data and if you’ll need to alter monitoring levels at runtime.
Feasibility
Finally, feasibility includes the ability to maintain and deliver the system despite time and budget constraints. Some things you need to consider for this principle are:
-
- Is it possible to meet the SLAs? For instance, is there a cloud provider that guarantees the uptime you need to provide to your customer?
- Do you have the necessary experience and skills in-house to build the cloud app, or will you need to hand it over to a third party?
- What trade-offs can you accept and how much can you spend on the operational costs, keeping in the complex pricing of cloud providers?
Features of a good cloud-native data platform
You now know the principles and architecture considerations you should keep in mind when making a cloud-native platform. Let’s now look at some more features that a good platform should offer.
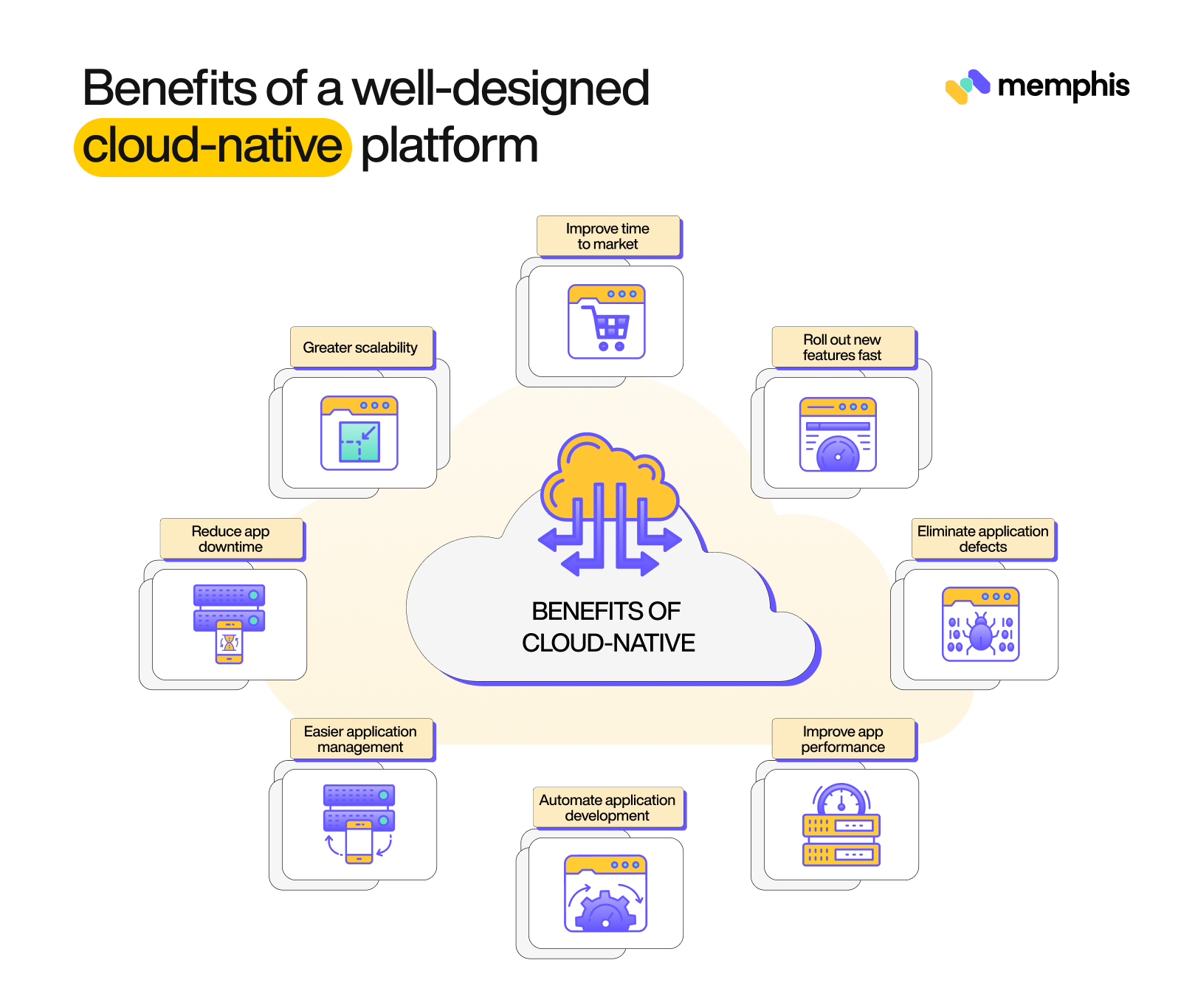
Benefits of a well-designed cloud-native platform (Source)
Cost-efficiency
It is true that there’s a big difference between the cost of fully managed cloud services and on-premises/self-managed services. However, the elasticity of the former and the pay-per-use model followed by most cloud platforms make it possible to run the right size without any resource (and, in turn, cost) wastage.
This also means you don’t need to worry about spending extra to pay for unused resources or even deal with capacity planning. Plus, because of the multi-tenancy of cloud platforms, it’s possible for service providers to price their service at a much lower cost as compared to self-managed services.
Pay for what you use
As mentioned above, most cloud platforms follow a pay-per-use model, which means you’ll only have to pay for the resources you use instead of the resources provisioned. These resources can be both high-level (like API get and put requests) and low-level (like memory or CPU usage). So, unlike the case with on-premises data, you don’t need to pay for the licensing cores that you might not use at all.
Elasticity & scalability
A good cloud-native platform also includes services that can be scaled up or down with a simple API call or a single click. It’ll be even better if the platform can scale the services automatically depending on the defined policies. Plus, because of pre-managed capacity planning and elastic scaling, only the most extreme cases will expose the scalability limits.
Availability
An efficient cloud-native platform is also defined by its high availability and is designed to handle most failures. Most platforms offer a service level agreement of a minimum of 99.95%, which translates to 4.5 hours of downtime in a year, but in reality, you can expect a higher availability.
Multi-tenancy
Multi-tenancy has two benefits – manageability and economy of scale – that most cloud-native services benefit from. You can provide the best user experience to your customers with services like S3 that delivers the service as queries or requests instead of CPUs, and all the tenants are so well isolated that users don’t know that other tenants are also served by the same physical system.
Yes, in some cases, users do have to buy dedicated computing resources like memory and CPUs (as is the case with AWS Aurora), but the underlying infrastructure like storage and network is still shared.
Performance optimization
Finally, to be able to serve different kinds of customer workloads, your system should be scalable in multiple dimensions. The constraints should be aligned and optimized across the whole infrastructure, including the hardware, OS, and application. Plus, in the case of a managed system, there should be a tight feedback mechanism with production. The system should also have the ability to analyze and learn from different scalability and performance-related incidents and roll out improvements to optimize performance.





