Report Memphis.dev Cloud Performance And Load Report
Memphis
Here Is Why Memphis Should Be Your Next Message Broker

 Contents
Contents
Introduction
Times are complicated. Unfortunately, teams are shrinking, cost reduction is everywhere, and companies need to push for growth, which means more work with fewer hands. Among the never-ending challenges, tasks, features, and bugs, there is one thing that is constantly growing and becoming more complicated over time – data.
Within data, multiple categories exist, like data streaming, batch processing, pipelines, data warehouse, and databases.
There is a layer that resides in the middle and connects the different components – The message broker.
What does it take to reach production with a message broker?
- Centralized Monitoring for clients to infrastructure. Many variants can cause infrastructure and client breaks, and often it’s hard to get to root-cause.
- Autoscaling. Unpredictable scales and workloads are commonplace. You should be able to handle it using an automatic policy.
- Self-healing coverage. Multiple scenarios like network lags, unbalanced brokers, consumer crashes, and schema transformation rather than drop and a seal-healing mechanism can save you a lot of effort and time.
- A Dead-letter queue. For auditing and root-cause fixes. Depending on the use case, having a “recycle bin” is a much easier way to debug an async issue rather than a terse message or a trace.
- Retransmit mechanism. There are three states on the consumer side –
Listening, processing, acknowledging. If a consumer crashes during the processing stage before acknowledging the message, it should be known to both the consumer and the broker to retransmit that message, not the next one. - Storing offsets. To achieve the “e” section, it is the client’s responsibility to preserve already read and acked offsets, to understand what was read and what is needed to be retransmitted.
- Enforce schemas. Messages are being pushed from everywhere. The ability to enforce a single standard across the different producers is a must to enable a healthy scale.
- Real-time notifications. Make sure you are aware of anything. In the best case, if something went wrong on your streaming layer – you have failed to submit a BI report. In the worst case – you have failed to process payment transactions.
How Memphis solves all of those challenges?
Simplicity.
“What used to take three months in Kafka takes three minutes with Memphis. And with 90% fewer costs in the process.”
Memphis has been designed to be deployed as production-ready in 3 minutes, with a ZeroOps mindset, and exceptional DevEx.
Governance.
Schemaverse is a Schema management with versioning, GitOps, validation, enforcement, and zero trust. For Avro, protobuf, JSON, and GraphQL.
Monitoring.
Out-of-the-box monitoring with slack notifications and integration to all major monitoring platforms.
Each ingested message journey is traced.


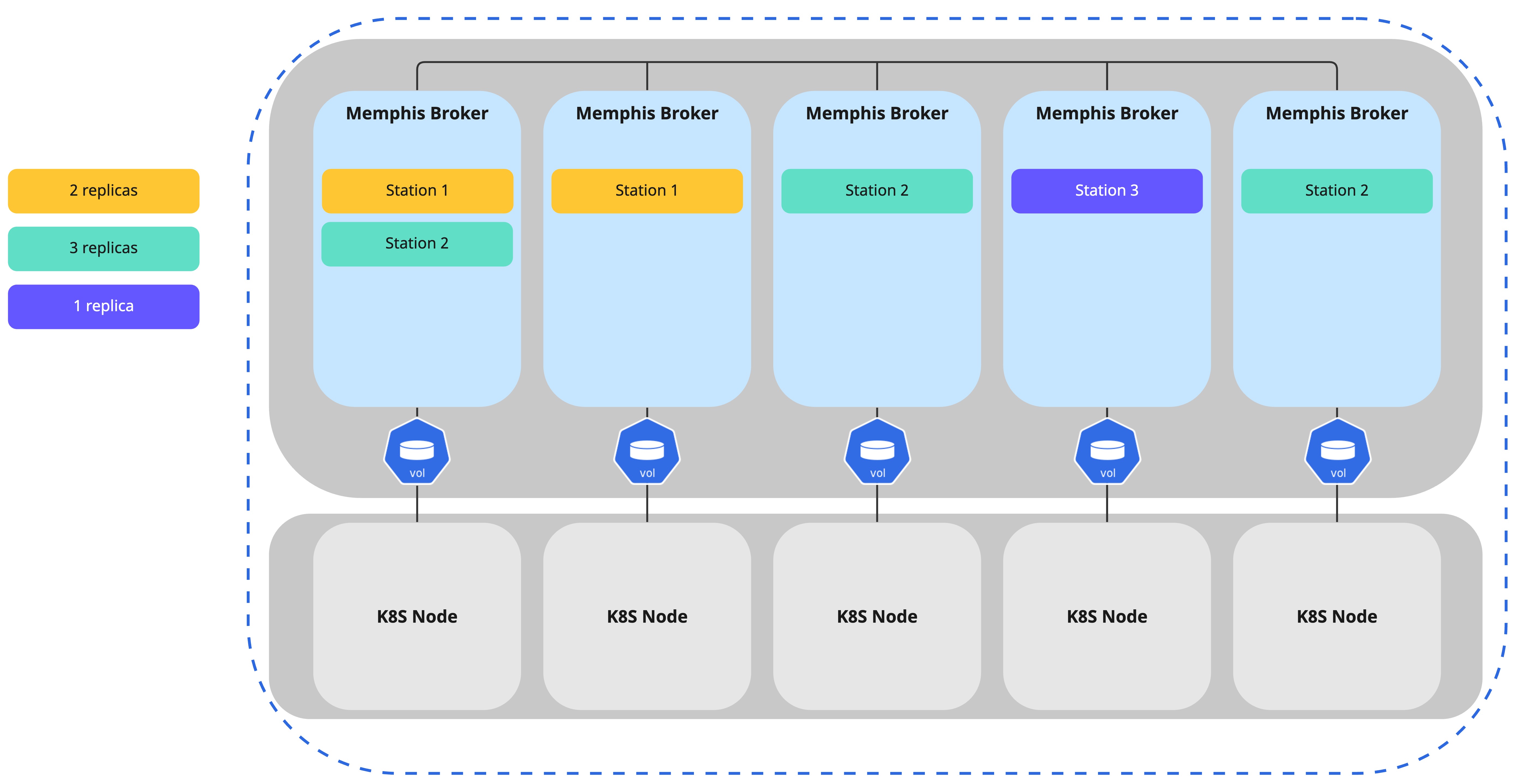
Scale-up and out.
Memphis is cloud-native by design and uses NATS Jetstream, which is written in Golang and runs on any kubernetes.
By running over K8S, scaling is easy and infinite. No zookeeper/bookkeeper. Memphis uses RAFT.

Less client responsibility.
Memphis offers a built-in DLQ with a retransmit mechanism, retransmit and offset record
are embedded within the SDK, so is self-healing policies to respond automatically for certain types of events.
Data Ingestion and processing.
Memphis processing engine provides true real-time processing with a full cover for all three needed layers –
Ingestion, transformation, enrichment.
Cost.
The usual implementation of a message broker till production will require
2 developers and 1 devops engineer for approx. of 6 months. The average cost for such a human effort would be approx. $300K, for implementation only!
Next is maintenance. Traditional message brokers/queues require constant care, manual scale, lag handling, stunning, onboarding new developers, throttling, and complicated troubleshooting, which ends up with more and more needed dev hours.
Last but not least, compute costs. In streaming, costs are derived from the needed throughput + storage.
Traditional brokers can easily reach an invoice of hundreds of thousands of dollars a month due to the lack of ability to scale down and in when needed.
Cost optimization and efficiency are one of Memphis’ main building blocks.
Implementation costs are close to zero due to the self-optimization that takes place when Memphis gets deployed, SDKs and client connectivity are built in a low code manner, and using Golang and kubernetes as its core foundations enables Memphis to run in a small footprint with the ability to scale down and in quickly.
Try Memphis. It takes only one command to install





