Report Memphis.dev Cloud Performance And Load Report
Customer stories
How gastromatic integrates systems using Memphis.dev

 Contents
Contents
Traditionally, the labor market in the hospitality industry is very volatile. On average people are working for nine months at the same employer. Furthermore, the software tools used to manage all the HR processes within 150,000+ companies are as diverse as companies themselves. Hiring a new employee therefore also means setting up the same employee again and again.
To tackle this problem, gastromatic, the leading HR-management software for the hospitality industry in Germany, developed a framework to synchronize all employee-related data between different systems using Memphis.
Used by thousands of active customers, this results in a countless number of messages synchronizing data between different systems day per day. As employee data is very sensitive data by nature, there are a lot of requirements such a system has to fulfill. The demands gastromatic had on such a system, thus, were quite high.
Memphis, as a lightweight cloud-native message broker, perfectly suits those requirements and abstracts a lot of work from the developers, giving them more time to focus on development and data engineering tasks.
Challenges of the Integration Hub
As the amount of microservices increases continuously in gastromatic, communication becomes more of a concern, thus we wanted to try out some new approaches.
Back in November 2022 we started with our Integration Hub. It’s the all-in-one ecosystem to sync employee-related data between different 3rd party systems. The goal is to make a future-ready dynamic solution, based on customer needs, which can take specific properties (like firstName, lastName, etc.) from the employees to sync them.
Since the Integration Hub is based on a microservices architecture (see the diagram below), it suits perfectly well as a case study on how to communicate between multiple services.
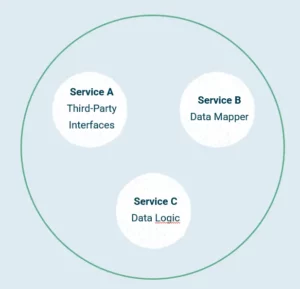
The first problem we came across was how we can make them internally communicate with each other?
Depending on the kind of communication we distinguish between sync and async communication.
Sync Communication
For those parts of the communication where we need immediate feedback, we decided to implement sync communication patterns. The main requirements regarding our sync communication were:
- Fast
- Reliable
- Typed interface
- Multi-language support
As we wanted to have a fully typed solution, we chose grpc over Graphql/Rest for our internal synchronous communication, using protos to define our interfaces. With its support for multiple languages, this allows us to develop microservices independent of the underlying language.
Async Communication
Besides the parts of our communication where we need sync communication, we also have a lot of scenarios where async communication suits perfectly well. This is especially the case when no immediate feedback is needed and scalability and reliability is of importance.
One example of such a use case would be Change Data Capture (CDC) design. Let’s consider the following fields of a table given in the picture.
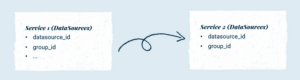
With a microservices architecture, we wanted to achieve total independence so there’s no/minimal coupling between different services. Even if Service 1 is down, Service 2 has to be able to process tasks. Therefore each service has its own database containing all data it needs. Using CDC we propagate each change in the DataSources of Service 1 to Service 2, which is having a subset of fields from the datasource table of Service 1.
Of course, we have to make sure that that all changes are propagated correctly, thus, we also have some requirements regarding our asynchronous communication:
- Event sourced (A new service should be able to replay all events)
- Exactly once (Each message should be consumed exactly once)
- Ordering (The messages have to be consumed and processed in the correct order
- Typed Interface
Why did we choose Memphis?
Queues are very well used in production environments. We already had experience with dramatiq and rabbitmq within other projects. We were certainly looking to improve upon our mistakes in Error Handling, which is a general problem in async Communication.
We first looked for solutions which are popular or fits the best to our use-case.
- Apache Kafka
- Memphis
- KubeMQ
- AWS SQS
- …
The most popular for sure is Apache Kafka with Debezium. Developed for a long time, Kafka does support all requirements we had. However, setting those up correctly and maintaining them needs a lot of effort. For example the support for typed message interfaces is not natively supported by Kafka. Instead you have to use an extra schema registry, e.g. Confluent Schema Registry, AWS Glue, etc. Our SaaS platform is further based on multiple independent instances of multiple applications operating in a shared environment. Kafka doesn’t support multi-tenancy natively. In order to run, complex configurations are a requirement. Thus we were looking for other, more lightweight solutions. Hence, we came across memphis. Memphis claims to push the next generation of applications, especially SaaS-type architectures, Memphis supports Multi-tenancy across all layers, smoothly integrating with Kubernetes — Sounds like a perfect fit for our needs.
We quickly made a small prototype with both — Kafka and Memphis — to check which one fits our use case the best. And indeed it felt smooth to deploy and integrate Memphis into our existing cluster infrastructure.
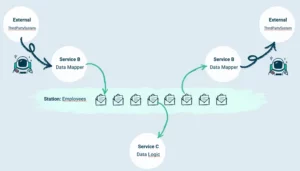
Here are some of the points we observed where Memphis stood out:
- Resources: Kafka being infrastructure-heavy needs 6 nodes whereas Memphis only needs one (two for high availability).
- Memphis is easy to deploy — really it is. No need for hours of configuration.
- Memphis, same as Kafka, supports an exactly once and at least once policy for consumed messages.
- Schemaverse: Memphis introducing schemaverse and version management was neat. Not only does it support proto types, types are now also checked natively, no need for an extra schema registry anymore.
- Fast responses from the (Memphis) developers, and feature requests are directly taken into consideration.
- UI: The intuitive UI for Integration and Monitoring is a nice feature and also feels more natural than several solutions for Kafka.
Lastly, points we saw as a disadvantage:
- Memphis in Beta: Although not a huge bummer. We evaluated the roadmap of V1 release, and this aligned with our project release.
- Compaction: Currently Memphis, in contrast to Kafka, doesn’t support automatic compaction. This is a must have feature, which also is on the roadmap of memphis.
- CDC: Memphis is still missing CDC support. Although it’s on their roadmap and hopefully it will be done soon.
- As a widely used tool, it’s easier to find developers with experience in Kafka (but honestly, isn’t it much cooler to learn something new?)
Since our use case doesn’t really require a heavy CDC approach and we do not want to spend too much resources for DevOps, we went for a simpler solution first and chose Memphis over Kafka based on our observations. For now, we implemented our own compaction approach, but a native solution would be great here.
How is Memphis seamlessly integrated with the Integration Hub?
As already mentioned, deploying memphis is really easy. In our case we added it to our existig Flux settup and deployed it in a separate namespace in our clusters. We further created stations (queues) for all kind of data that should be synced between services.
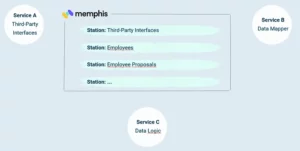
The question was now, how to configure the stations in order to fulfill our requirements.
As mentioned before, our main objective is to sync employee data. Naturally employee data is very sensitive and the correctness of the data is of utmost importance. Not only because of the strict GDPR regulations in Europe.
Therefore when syncing employee data, we have to ensure that the order the messages are processed is correct. Imagine two name changes. If the latter is processed before the first, e.g. because of network latency, the name would be incorrect. The correctness of the order in Memphis is achieved by grouping all consumers of one service and listening for name changes in one consumer group.
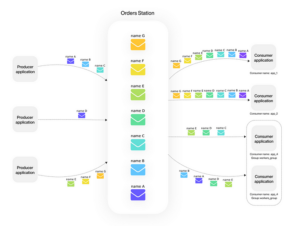
This allows us to ensure the order of the messages, even when we are scaling up the consumers. Note that Memphis is internally operating on one partition per consumer group, which makes this possible. So while in Kafka you can specify the partition a message is sent to by using a custom logic to generate message keys, probably a hash method, Memphis is depending on consumer groups.
Furthermore, setting the policy to exactly once, we can ensure that each message is processed only once. This is totally possible in Memphis. As from our experience, an “exactly-once” policy can be quite expensive. This is why we are not using this feature yet. Instead we ensured that our messages are idempotent throughout the whole process. But for sure we will test it out in the future.
In our use case, each third-party system we are integrating is handled by a separate consumer group. Here, we can profit from the flexible retention policies in Memphis, up to storing them in a S3 bucket. Setting the retention period very high results in a defacto event sourcing. When we start up a new consumer group, the group first consumes all messages that are already available in the station (configurable of course). There is no need to initially pull the data from a database.
Further the whole history is collected. Imagine a case where the salary of an employee changed multiple times. If the third-party system is responsible for the payroll, it is quite important to have all those changes and not only the latest state.
Nevertheless, a completely event sourced approach also leads to a huge amount of data that needs to be stored. Basically, all your data is duplicated. Thus, a smart compaction logic, allowing to set the retention period to a reasonable value without losing data, would be nice.
Another point is the scalability of our system in terms of integrating new systems. New third-party systems might need new interfaces. The seamless integration of the schemaverse ensures that we are not breaking any existing integrations by accidentally changing the message making it incompatible with existing systems. At the same time, since Memphis allows versioning of schemas, the backward compatibility is ensured.
Final Remarks
Overall we are currently running 12 Stations each having multiple consumer groups with multiple consumers on multi-node EKS cluster. Until now, we never experienced any issues with data loss. The extensive UI helps us to track the state of our memphis cluster in our daily work, pointing to dead messages and highlighting issues in the cluster.
The next steps on our roadmap are to include S3 buckets to persist messages and to improve our compaction logic, if possible by applying a native solution from Memphis.





