Report Memphis.dev Cloud Performance And Load Report
Comparisons
What is Python Celery? Python Celery vs Memphis

 Contents
Contents
When it comes to data-intensive applications, tasks that take more than a few seconds to complete slow down users. Users today expect pages and apps to load instantly, and if they don’t, they chalk it up to a poor user experience. To prevent that from happening, you can make use of Celery or Memphis.
But what is the difference between Celery and Memphis, and what are both of these used for? Let’s get started.
What is Celery Python?
Celery is a distributed task-processing system that allows you to offload tasks from your app and can collect, perform, schedule, and record functions outside the main program. By integrating Celery into the app, you can send time-intensive tasks to its task-processing system so that your web app can continue to respond to users while Celery works on completing operations in the background asynchronously.
To get started with Celery tasks from the main program deliver results to a backend, and run the Celery task-processing system, Celery needs a message broker (handler), like Redis for communication.
Understanding task queues
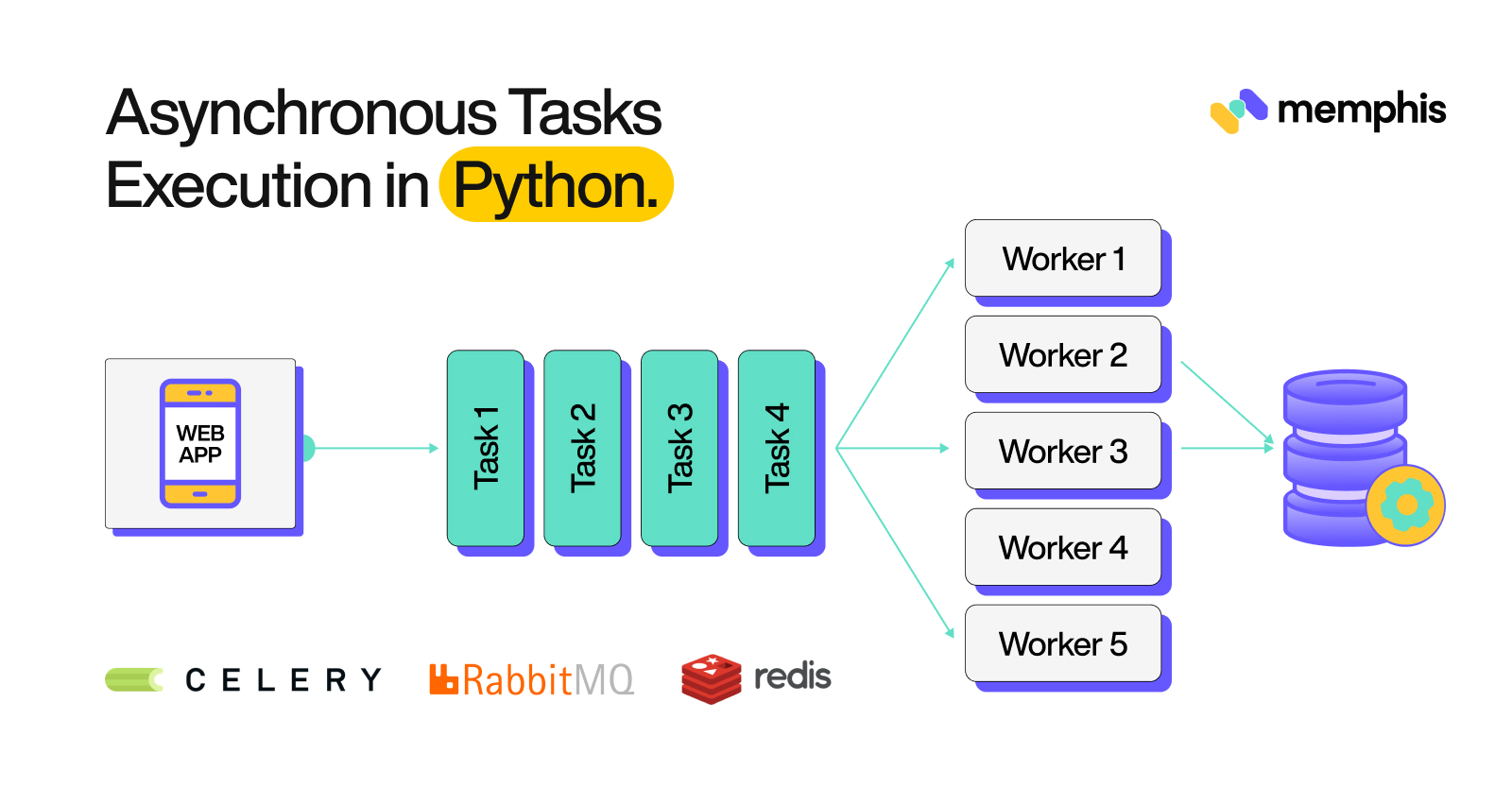
Think of task-processing systems as mechanisms that can be used to distribute work across machines or threads. The input for a task-processing system is a unit of work termed a task. Worker processes specially designed for this purpose monitor the task-processing systems for new work.
Communication in Celery takes place through messages, typically with a mediator to facilitate communication between the worker and the client. The task-processing system works something like this: when a client wants to initiate a task, it adds a message to the task-processing system. A mediator then relays the message to a worker.
Since a Celery system can have multiple mediators and workers, it makes horizontal scaling and high availability possible. And while it’s written in Python, you can implement the protocol in any language. You can also make language interoperability possible with webhooks.
Why Celery?
Most developers tend to use Celery for two main reasons:
- To offload work from the app to distributed processes that run independently of the app (using Celery workers).
- To schedule tasks to execute at specific times, and as recurring events in some cases (using Celery beat).
It’s a great choice for both of these tasks because it’s a task-processing system that focuses on real-time processing and supports task scheduling. You can also make use of Celery to accomplish goals, such as:
- Defining independent tasks that can be executed as functions by your workers
- Listening to a message handler to receive new task requests
- Assigning incoming task requests to workers for execution and completion
- Monitoring the status and progress of workers and tasks
Celery use cases
Celery can be used in numerous web applications since you can use a distributed task-processing system for multiple tasks, like the following:
- Data analysis: Making sense of data is always resource-intensive and if all the data analysis happens right within Django, your app can become unresponsive.
- Image processing: You may want to perform some tasks on images that users upload or share, like resizing the images or encoding them. This is a resource-intensive task since it can slow down the app, especially if you have a large user base.
- Email sending: Sending emails like verification emails, confirmation emails, or password reset emails can take some time and slow down the app, particularly if there are many users.
- Text processing: If your app allows users to enter some data, you might want to keep an eye on their input, like translating the user input to some other language or checking for foul language. But if you handle all of this within the web app, it can greatly affect performance.
- Report generation: If your app involves generating reports from user-provided data, then you know that generating PDF files takes time. Allowing Celery to handle this task in the background instead of letting the app freeze can help you provide a better user experience.
- Running machine learning models: Waiting for results from some machine learning operations can take more than a few seconds. So instead of allowing the users to wait while the calculations are completed, you can let Celery handle it while allowing the users to continue browsing until you get back the results.
- Web requests like API calls: If your app makes web requests to provide some services, there’s a high chance that you’ll come across unexpected wait times. It’s better to allow these requests to be handled by different processes.
Managing multiple components are daunting!
Why not do task scheduling in one component?
Explore more

What is Memphis?
Memphis is an open-source real-time data processing platform that uses the Memphis distributed message handler to offer end-to-end support for in-app streaming application scenarios.
You can think of it as a durable, robust, and simple cloud-native handler within an ecosystem that allows reliable and fast development of event-driven application scenarios. It focuses on four main pillars:
- Stability: Makes sure that brokers and queues are stable and highly available since they play a crucial role in the structure of modern applications.
- Efficiency & Performance: Ensures efficient resource consumption and good performance.
- Observability: Cuts down troubleshooting time to almost zero.
- Developer Experience: Offers inline processing, schema management, modularity, and rapid development.
Understanding message brokers
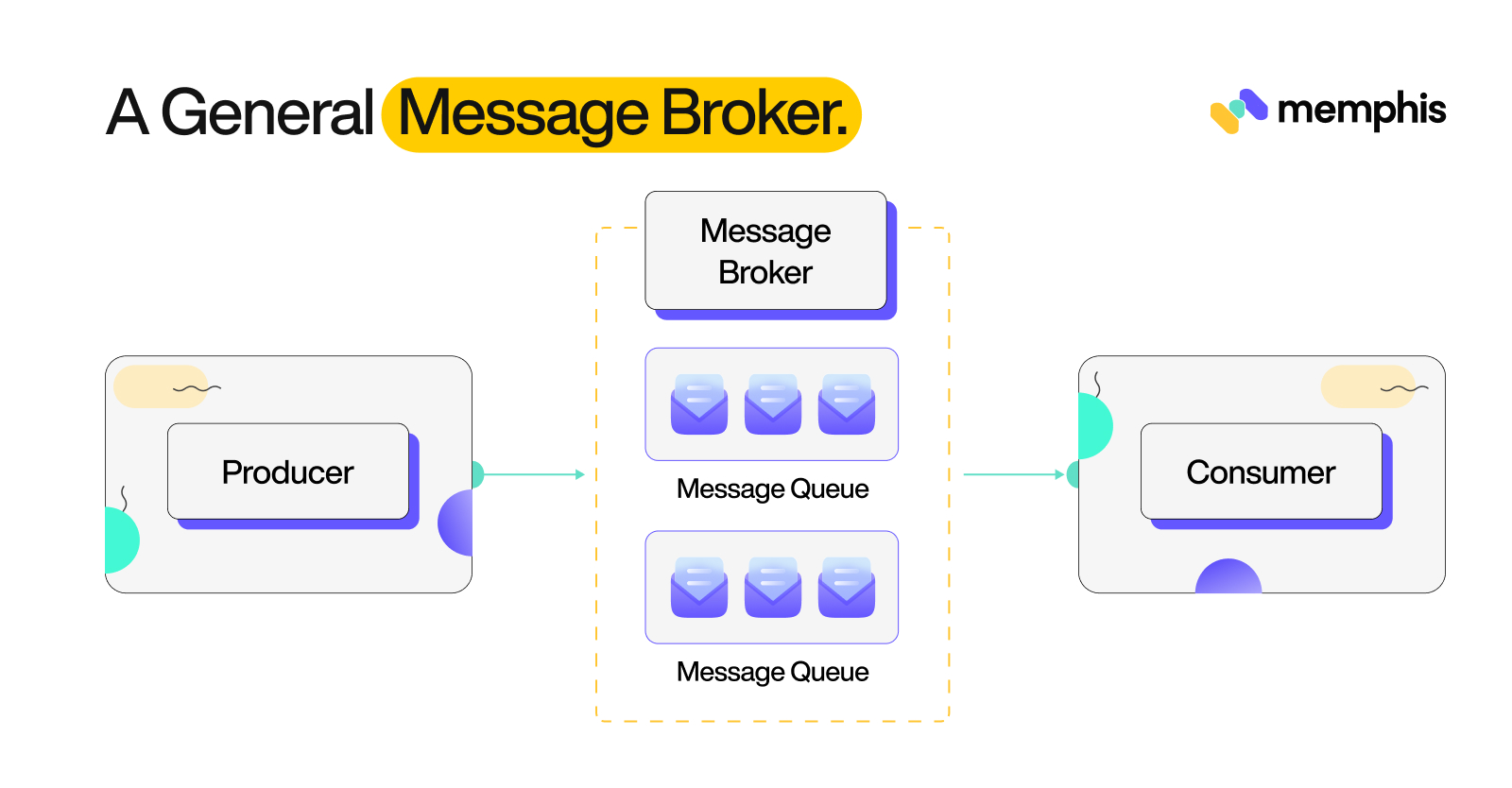
A message handler is essentially software that implements some architectural pattern for message routing, transformation, and transportation. It allows for communication between applications while implementing decoupling to minimize the awareness that the apps have of each other to exchange messages.
The main purpose of the handler is to accept incoming messages from apps and perform specific actions on them. It can execute a variety of tasks like enabling the use of intermediary functions, decoupling endpoints, and meeting non-functional requirements.
Some common application scenarios of message handlers include:
- Netflix uses message handlers to take in different user events and distribute them across different data stores and systems for things like BI, analysis, ML training, trigger actions, etc.
- Uber uses it to update their maps and the location of the drivers in real-time.
- Queuing and task scheduling for stateless workers.
- Mesh communication among microservices.
Why Memphis?
When your app needs a message queue, you first need to do a number of things, in addition to onboarding new developers and learning all the concepts through courses, ebooks, documentation, etc. These include:
- Creating observability
- Building a dead-letter queue
- Creating client wrappers
- Handling back pressure
- Building a scalable environment
- Configuring real-time alerts and monitoring
- Creating a mechanism for retrying
- Dealing with ACLs
- Creating cloud-agnostic implementation
Instead of spending a good chunk of time on all these things, you can just use Memphis and spend your time and resources on things that matter more.
Memphis can solve a number of other problems as well that developers often face. It’s the ideal option to use when:
- There are numerous data sources that become very difficult to handle.
- Different, complex schemas come in the way.
- It’s hard to transform schema and analyze the streamed data per source.
- You need to stitch numerous applications like NiFi, Flink, and Apache Kafka for stream processing.
- There’s a loss of messages because of a lack of retransmits, monitoring, and crashes.
- It’s challenging to troubleshoot and debug an event’s journey.
- Message queues like NATS, and Kafka become hard to onboard, tune, update, deploy, secure, and manage.
- Converting batch processes into real-time becomes time-consuming and complicated.
Memphis use cases
Memphis is great for a number of uses, including the following:
- Asynchronous task management and communication among services on Kubernetes
- Data ingestion and queuing
- Real-time streaming pipelines
- Multiple destinations for one message
- Informing various third parties of different events
- Collecting data from different sources
- Marketing funnels
- Sending just one notification for more than one alerting channel simultaneously
- Real-time text/post scanning
Comparison of Python Celery and Memphis
| Feature | Celery | Memphis |
| Architecture pattern | Pub-Sub | Produce-consume |
| Open source | Yes | Yes |
| Asynchronous | Yes | Yes |
| Scaling | Horizontal | Horizontal and vertical |
Celery is a flexible, reliable, and simple distributed system that can process huge volumes of data while providing the tools needed to maintain the system. In other words, it’s a task queue that focuses on real-time processing and supports task scheduling. Meanwhile, Memphis is a real-time data processing platform that offers complete support for in-app streaming application scenarios.
Similarities
Both tools have their differences and similarities. Let’s first take a look at the similarities in more detail.
Architecture
Both Memphis and Celery follow the produce-consume design pattern, where each message produced by a producer is consumed by just one consumer. This mechanism works to distribute work among multiple consumers.
Open-source
Both Memphis and Celery (licensed under BSD License) are open-source with a diverse community of contributors and users. In fact, Memphis states that the community can help build truly disruptive technology.
Deployment
Memphis is not just cloud-native, but it’s also agnostic to Kubernetes on any cloud. So, you can deploy Memphis on the cloud (AWS, GCP, DigitalOcean, & Azure), and over Kubernetes and Docker. The same goes for Celery – the process might be a little longer and slightly complex, but you can deploy your Celery workers on a cloud service or using Kubernetes.
Other similarities
- Both allow asynchronous task management (and can also work synchronously).
- You can scale horizontally using both tools (but Memphis also allows for vertical scaling, too).
- Both use a message handler. For Celery, you can use either Redis while Memphis uses its own Memphis-distributed message handler.
Differences
The primary difference between Memphis and Celery is that the former is a complete system for data processing, while the latter is primarily a task queue that you can use to offload tasks from your app.
Vertical scaling
Memphis allows for vertical scaling with the addition of memory, storage, or CPU to each handler. As more data is transferred and the workload is increased, more computing resources must be allocated. One way to do that is to strengthen the Kubernetes nodes with more CPUs or more storage or memory based on the station’s storage preferences.
Since production-level Memphis runs only Kubernetes, it won’t affect Memphis and you won’t experience any downtime. Instead, you’ll be able to enjoy better relative speed and more simplicity. Increasing your resources can increase throughput and even improve dynamic memory performance. Plus, even if you increase the size of the system, the software configuration, and network connectivity don’t change, so you don’t have to worry about running into problems.
Meanwhile, Celery doesn’t allow vertical scaling.
Application Scenarios
Both tools are suitable for different application scenarios, even though some of them tend to overlap. Celery is a distributed task queue that allows you to offload tasks from the app and execute them outside the main program, allowing it to continue running. Examples of such tasks include report generation, text processing, data analysis, image processing, and email sending.
Memphis can also work as a queue for task scheduling, but with an added bonus: it’s more scalable than Celery. It also aims to enable rapid development, cut down costs, eliminate coding barriers, and save development time for data engineers and data-oriented developers. It aims to solve challenges that often occur due to real-time processing and ingestion. Some common application scenarios for Memphis have already been discussed above.
Architecture
The way both tools work also differs.
Django creates a task and requests Celery to add it to its task-processing system, which does so into Redis, or something similar so that Django can continue to work on other things. Meanwhile, Celery runs workers on a different server that can assign tasks to themselves. The workers listen to Redis and when there’s a new task, a worker picks it and processes it, and then relays the result back to Celery.
Meanwhile, in Memphis, producers publish or push messages to a Memphis station (a distributed unit for storing messages, much like queues in Celery and RabbitMQ) created on a Memphis broker. They can also send messages to the broker asynchronously or synchronously. Consumers subscribe to the relevant Memphis station and pull messages from it. RAFT is used to maintain data coordination among brokers like status details, date, location, and configuration.
Notifications
Memphis allows you to get notifications and alerts right to your chosen Slack channel to enjoy better real-time observability and faster response time. And as you can see here, implementing it is pretty easy, too.
However, when it comes to notifications in Celery, things are a lot trickier. You’ll have to do things from scratch, which means configuring the message broker of your choice, creating the necessary models and a notification trigger, and connecting everything together.
Performance
To set up and make use of Celery, you basically need to configure two components: the queue itself and a DB. Meanwhile, when it comes to Memphis, you only have one component to worry about, and that is the Memphis broker itself.
Plus, benchmark tests done on the two prove that Memphis performs much better. According to different tests, there’s quite a considerable time delay between when the tasks are triggered and when they’re consumed by Celery workers.
It’s also important to mention that Memphis can process 300K messages per second per station.
Observability
Memphis also fares much better than Celery when it comes to observability. With Memphis, you get full Infra-to-cluster-to-data GUI-based observability, real-time message tracing, monitoring, and notifications embedded within the management layer. However, there’s no GUI in Celery, making it difficult to observe and troubleshoot problems
Celery in compare to Memphis.dev
In addition to being open-source and free, Celery has the following benefits:
- It supports multiple message handlers, like Redis, RabbitMQ, Amazon SQS (though it lacks features like remote control and monitoring), and Apache Zookeeper.
- It integrates with multiple web frameworks like Tryton, Tornado, web2py, Flask, Pylons, and Pyramid.
- It allows you to define both simple and powerful workflows with powerful primitives like chunking, chaining, and grouping.
- It allows you to specify when to run the task and set up periodic tasks for repeating events.
- You can also control the number of tasks to be executed per unit time and how long the task should be allowed to run.
Meanwhile, its limitations include the following:
- It lacks user support, particularly for large enterprises looking for a production-grade solution with high availability.
- Like most open-source tools, Celery focuses more on expanding the features it provides instead of ensuring a simple user experience. This means it has a steep learning curve.
- Even though Celery provides support for integration with numerous third-party software, these integrations can be a little tricky to figure out.
Memphis is a great option for real-time data processing for the following reasons:
- Memphis is designed with simplicity in mind. It can be deployed as production-ready within three minutes and is made with an exceptional DevEx and ZeroOps mindset.
- It makes schema management easy with Schemaverse which has features like zero trust, enforcement, validation, GitOps, and versioning for GraphQL, JSON, protobuf, and Avro.
- It provides out-of-the-box monitoring with Slack notifications and integrates with the most popular monitoring tools so that the journey of each ingested method can be traced.
- Memphis is designed to be cloud-native and runs on any Kubernetes, which makes scaling easy and infinite. There’s no bookkeeper or zookeeper involved.
- It’s designed such that your data engineering team has to make minimal additions to it. And since it’s modular, your team can directly add more capabilities to the system, if needed.
- Memphis ensures fast, resilient, and true real-time processing with just one tool (instead of a combination of tools like Kafka for ingestion, Flink for processing, and NiFi for transformation) right to the app using the serverless frameworks of the cloud.
- Compared to other processing tools and message handlers like Pulsar and Kafka, Memphis is 140% less expensive.
- Other benefits include a small footprint, an efficient proprietary compute scheduler, and better resource allocation.
Conclusion
In this tutorial, you learned that both Celery and Memphis are good options for asynchronous task management. While Celery lets you offload tasks and allow users to continue using the app, Memphis is one of the best tools for data processing. The best thing about it is that it serves as an all-in-one tool that includes all that you need, which takes away the hassle of configuring the integration of different tools.
So while you can make use of Celery to offload tasks from your application to independently-running distributed processes and schedule task execution at certain times, Memphis is great for cloud-native applications and takes care of all the things needed for quality data streaming.





