Report Memphis.dev Cloud Performance And Load Report
Customer stories
Real-Time Cyber Threats Identification: KELA & Memphis.dev

 Contents
Contents
About KELA
KELA is one of the world’s leaders in preventing cybercrime using its state-of-the-art end-to-end platform and a team of experts that constantly gathers intelligence on potential threats, profiling the actors and potential attack vectors, and works closely with the in-house teams to prepare and prevent the potential threat.
KELA serves thousands of customers worldwide and processes millions of potential threats per day.
KELA’s use case
As the landscape and volume of potential threats constantly grow, the collection of fresh daily data grows exponentially as well, new sources are added by the day, and output should be processed in near-real-time latency.
An overview of the steps in a common identification and profiling pipeline will usually be built in the following manner –
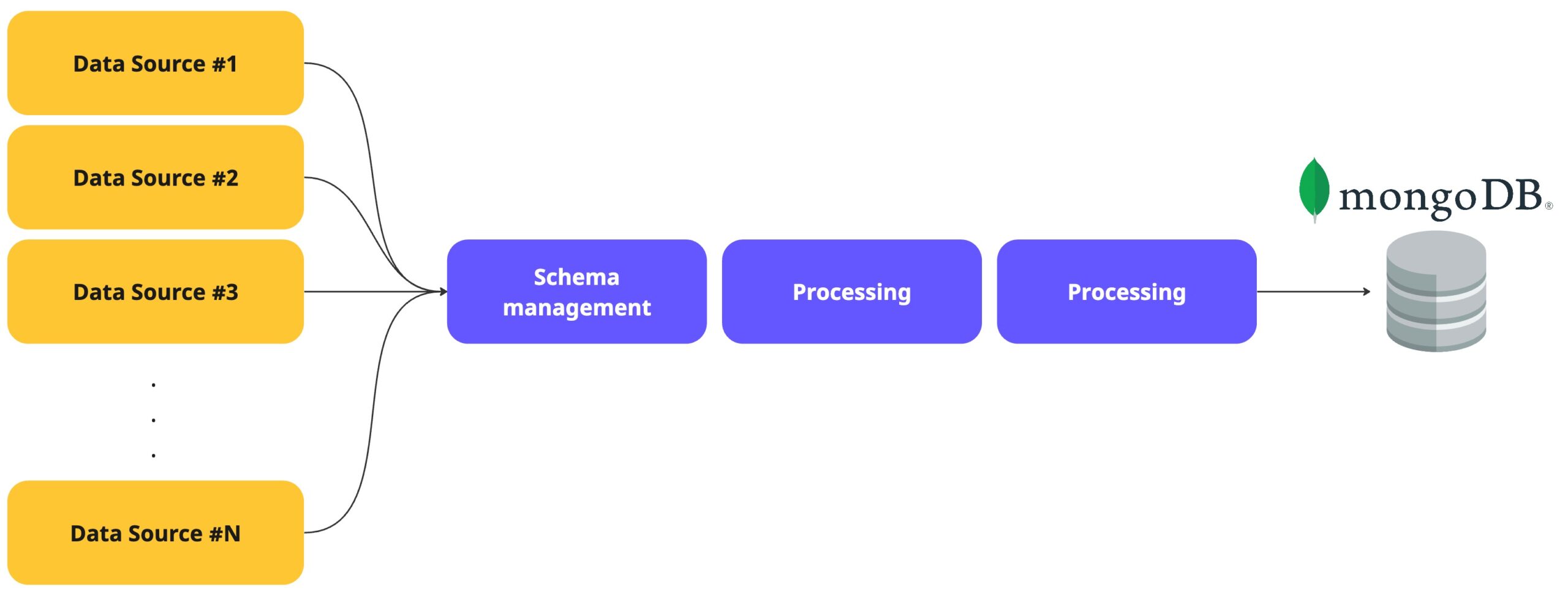
A bit more over the architecture –
- Different collectors collect data using various methods.
- Depends on the decided pattern – in some cases, the collector itself will be the schema funnel, and in others – a dedicated step will be built to align ingested data structure.
- The following steps would be functions that enrich and process the ingested data. In some cases, data in motion will be checkpointed within temporary tables in the database.
- Right after MongoDB, a visualization layer will collect the data and present it in a real-time dashboard, which constantly listens for changes and re-renders the components.
The added scale in the form of more data to collect from more sources revealed several challenges and requirements –
- Ingest data at scale in real-time latency.
- Ability to absorb a great number of connections at once.
- Reliable data movement with a checkpoint at first land.
- Non-volatile persistency of moving data.
- Scale specific pipeline stages per source and more additional attributes.
- Evolve and modify pipeline stages easily and reliably.
- Ensure data governance and standard schema across multiple data sources.
- Easy to maintain and lower management overhead as possible
- Cost per usage
To answer the above requirements, a new paradigm had to be adopted in the form of microservices, distributed, and cloud-native pipeline architecture.
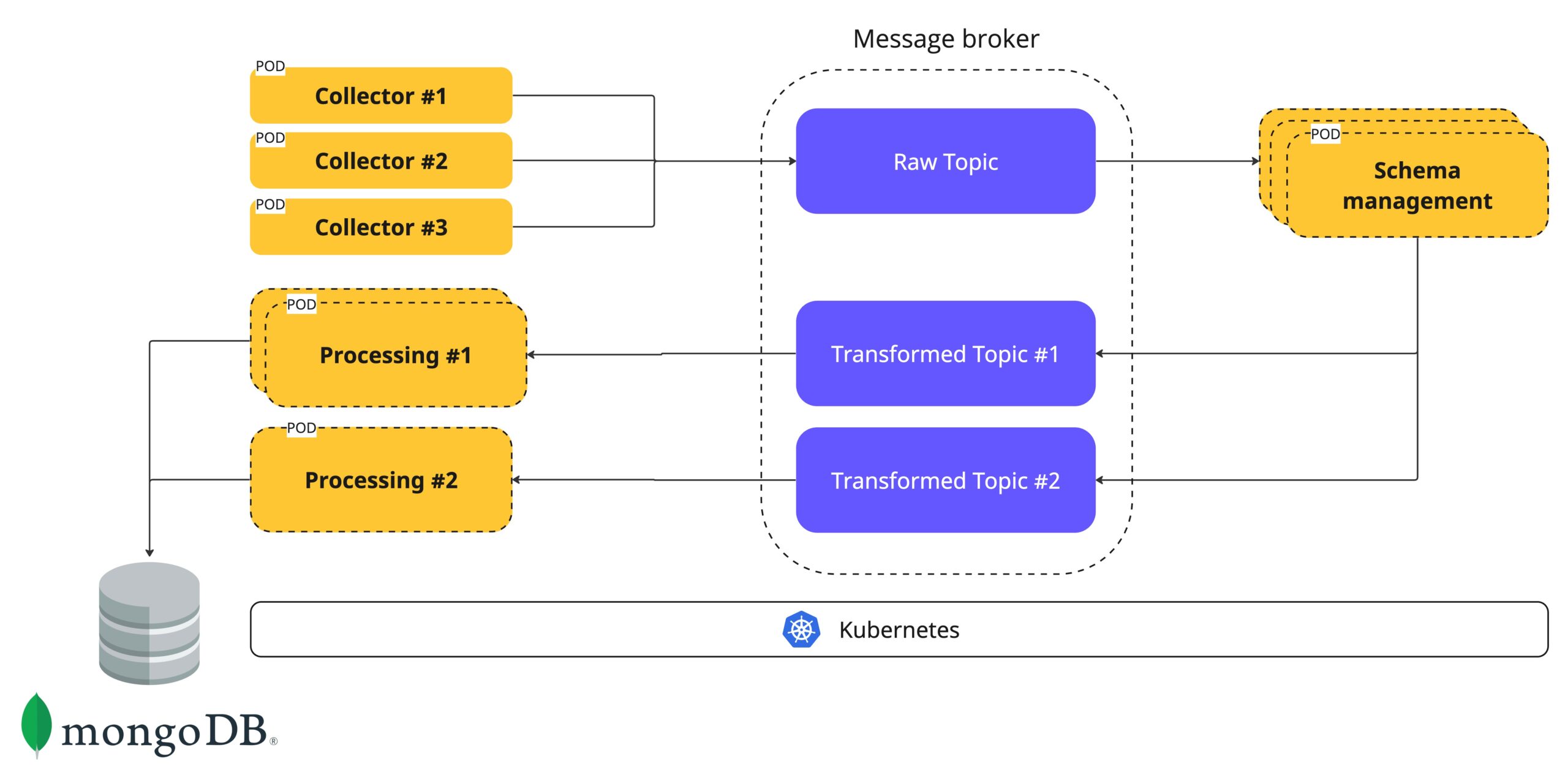
A couple of reasons behind the architecture
- Each yellow square represents a stage.
- Each stage is a different microservices responsible for a specific task.
- The different microservices and stages run on Kubernetes to utilize K8S life-cycle management and scale elasticity.
- Due to the cloud-native nature, each service can be specifically scaled and based on request or environment metrics.
- The message broker in the middle is responsible for the data movement at scale between different services in an async manner.
- Message brokers, in comparison to databases, are built for a great number of connections, strong persistency, workload bursts, high throughput, and high-velocity data transfer in comparison to p2p HTTP-based communication between microservices.
KELA and Memphis.dev
When KELA first approached Memphis.dev, there was an active movement towards using managed Kafka as the engine behind the architecture.
The exploration of Kafka also derived from the in-house skills and personal experience of some of the team members.
KELA’s main factors for choosing the right technology
- Cost
- Ease of use
- Operations’ simplicity
- Developer-oriented observability
- Time-to-value
- Reliability
- Performance
- Support and service
How Memphis.dev answers the above
- Cost.
Memphis, as an event processing platform, is up to 50x more efficient than legacy message brokers and event streaming solutions.
It is enabled by the nature and architecture of the broker itself, which is extremely lightweight, written in Golang (No JVM), requires minimum resources to initiate a fully operational highly-available cluster, and is not to take for granted – it takes minutes to onboard Memphis and start ingesting data which reduce a great amount of implementation time, and therefor more cost.
Memphis offers a fully managed and hosted Memphis platform with a usage-based cost structure.
Another key feature that helped KELA make its decision is Memphis storage tiering which enables operators to offload messages to S3-compatible storage for longer storage retention and achieve lower storage costs. - Ease of use.
Memphis offers a very simple yet powerful graphical control plane with all the needed components and actions for both developers and operations engineers.
Observability, real-time message tracing, graph overview, performance metrics, data-level observability for both stations and dead-letter stations, one-click integrations, and out-of-the-box notifications. - Operations’ simplicity.
Memphis is built for massive scale and complex event-driven use cases with fewer hands possible. - Developer-oriented observability.
Developer-oriented observability is different than plain observability. Memphis is making significant efforts to provide the right views and metrics developers require to build fast and troubleshoot application issues which often occur when working in an async, branched application to the minimum.
Memphis tackles these requirements by providing an exceptional console with deep visualization over the station’s (=topic/queue) internal, crucial information about consumers, producers, all the needed metadata, what are the messages stored currently in the station, as well as in the dead-letter station for fast troubleshooting. - Reliability.
Both Memphis cloud and self-hosted distribution are fully stable and production-ready.
In terms of message replicas, each station can have its own dedicated replicas policy, which dictates how many replicas each message will have. Each replica is spread across different Memphis brokers. Memphis Brokers runs on Highly-available Kubernetes and benefits from its life-cycle management as well.
Brokers are spread across multiple availability zones, constantly running through periodic encrypted backups, and sync with other regions and public clouds. - Performance.
Memphis has a RAFT-based distributed architecture with both vertical and horizontal scaling options, and for enterprises, there is an option to have a direct link between Memphis Cloud to the organization’s VPC. More on performance can be found here. - Support and service.
Customers and users are the most important thing. Their success is ours, and therefore we do our best to keep a close relationship with both our OS community and our cloud users.
Memphis Cloud offers 24/7/365 on-call, email, chat, and Slack support. SLA for severity 1 case stands for 15 minutes.
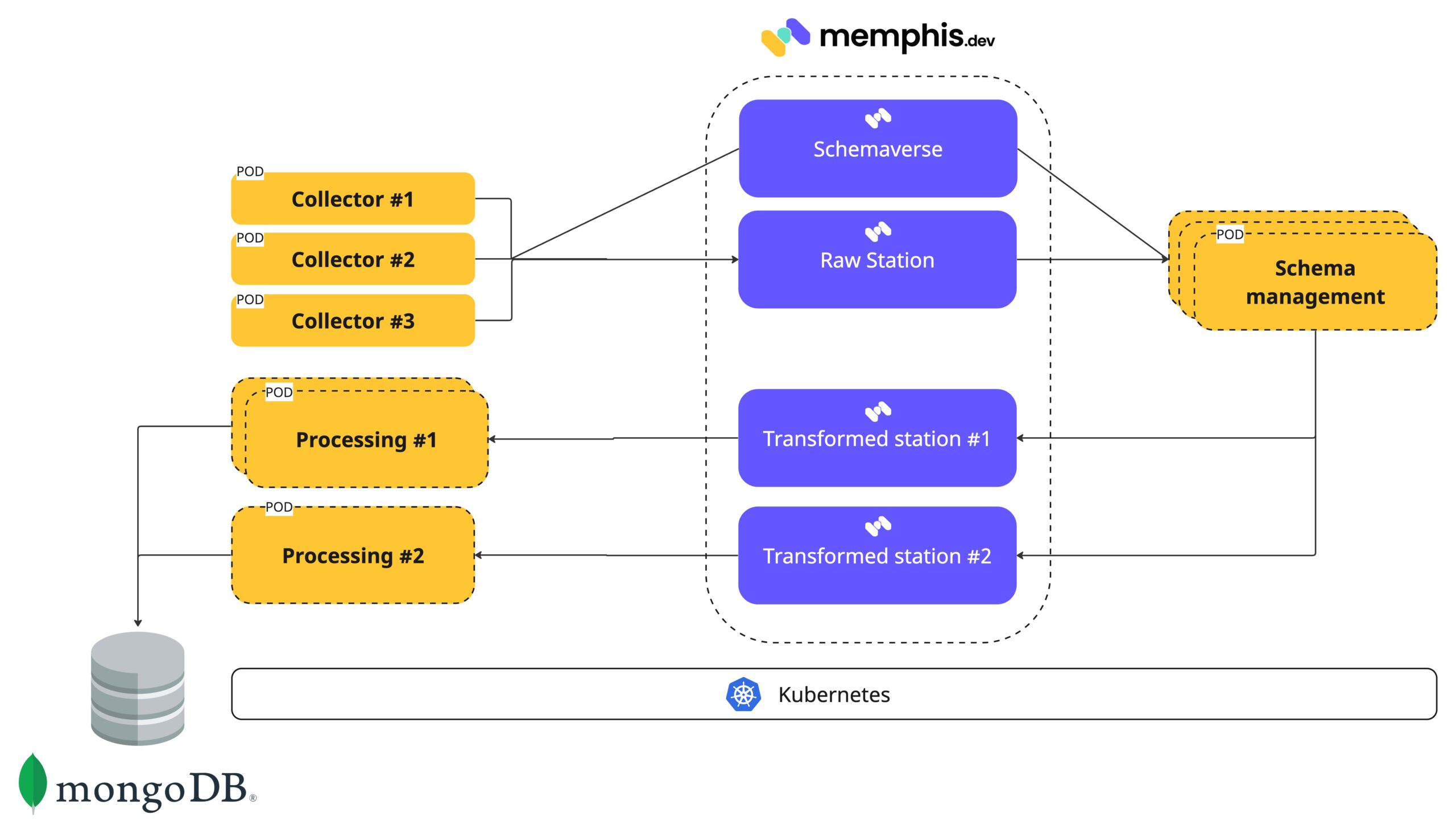
On top of the above list, the two key Memphis features that made KELA choose Memphis.dev are Schemaverse, out-of-the-box monitoring, notifications, dead-letter topic, and storage tiering.
Memphis Schemaverse provides a robust schema store, enforcement, and management layer on top of memphis broker without a standalone compute or dedicated resources. It also enables KELA to continue producing JSON objects and seamlessly convert them into protobuf. No code. No client reboots. Runtime updates. Transparent serialization.






