Report Memphis.dev Cloud Performance And Load Report
Data Engineering
Is Kafka a Message Broker?

 Contents
Contents
What is a Message Broker?
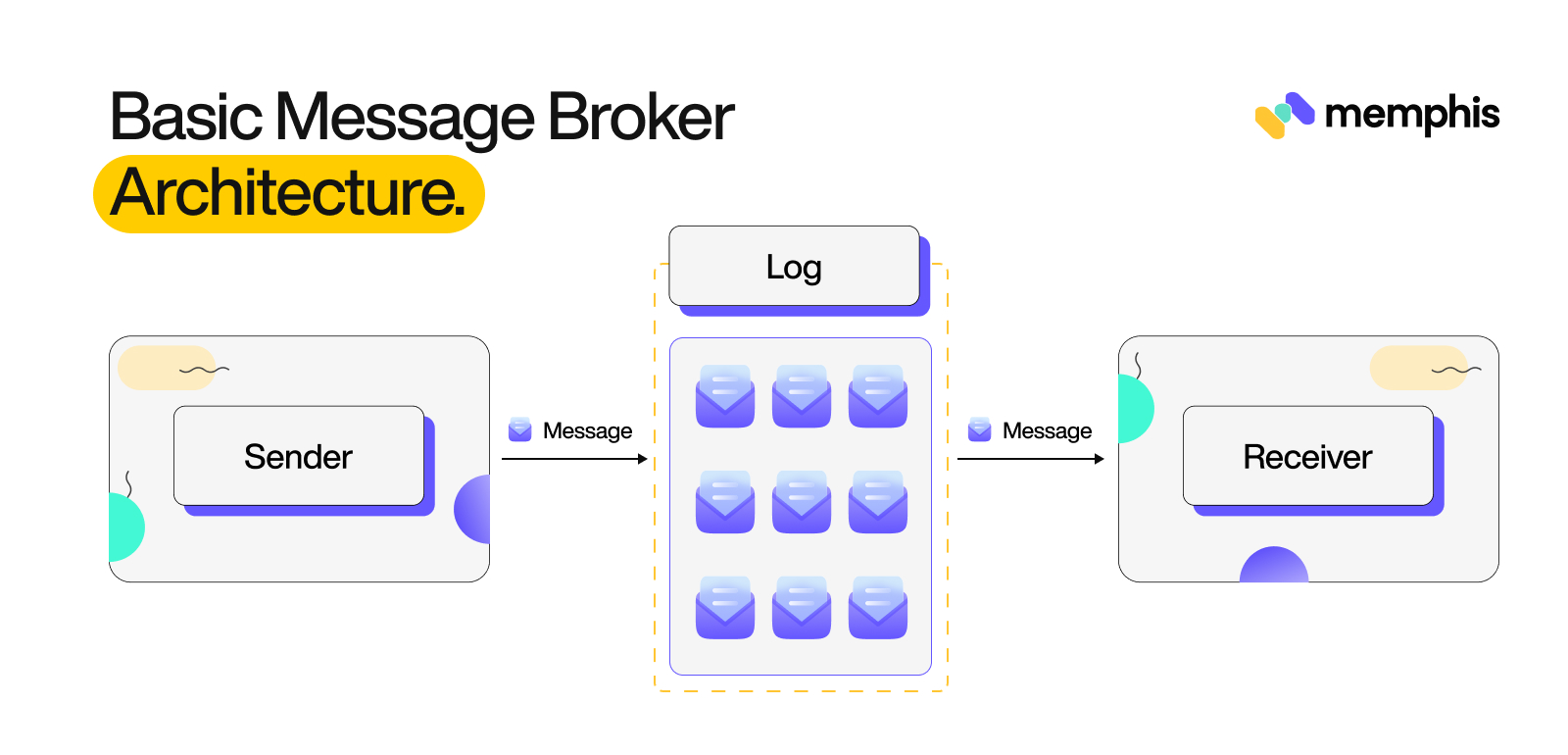
A message broker is a software component that can receive and forward messages without having each task wait for the previous one to complete(asynchronous interchange). These messages could be application logs, app-created events, or user-created events. Message interchange is essential for multiple use cases like establishing data lakes, real-time pipelines, event-driven features, microservices communication, log collection, asynchronous operations, and informing systems of necessary actions.
Message broker operates on the principles of the log data structure, which is similar to a queue. This data structure allows different clients to read messages from the latest or from an offset point in the past.
Core features of a Message Broker
Message brokers are an essential component of any event-driven or inter-service communication system. They act as the messaging system between different parts of a system, routing messages from one end to another in a reliable and secure manner. Message brokers’ core features include message routing, queuing, publish-subscribe functionality, and security measures such as message encryption and hashing. This section provides a more in-depth look at the various features of a message broker.
-
Message Routing
One of the primary functions of a message broker is to route messages between different clients and services. This is done using a routing key or a set of rules to determine where a message should be sent. This allows for messages to be delivered to the correct recipients without the need for direct connections between the sender and the receiver.
-
Message Queueing
Another critical feature of a message broker is the ability to queue messages. This allows messages to be stored temporarily if the recipient is not currently available to receive them. The message broker will then deliver the messages when the recipient becomes available. This ensures that messages are not lost and that they are delivered in the correct order.
-
Transactional-Messaging
A message broker also supports transactional messaging. This means that the message broker can ensure that messages are delivered reliably and in the correct order. This is done using a two-phase commit protocol to ensure that messages are only delivered if they have been successfully committed to the message broker’s storage.
-
External Connections
A message broker also allows for external connections. This means that it can connect to other systems and services that may be running on different platforms or in different locations. This allows for messages to be exchanged between different systems and services in a seamless and efficient manner.
These features of message brokers lend them to be an essential component of large-scale systems. There are different types of message brokers.
What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform that follows a publish-subscribe messaging model. This means that message senders publish their messages without any idea of the receivers. The receivers subscribe to the type of messages they need without knowing the sender. Kafka acts as an intermediary between these publishers and subscribers. The publisher’s messages are sent through topics, which are essentially pipelines for messages.
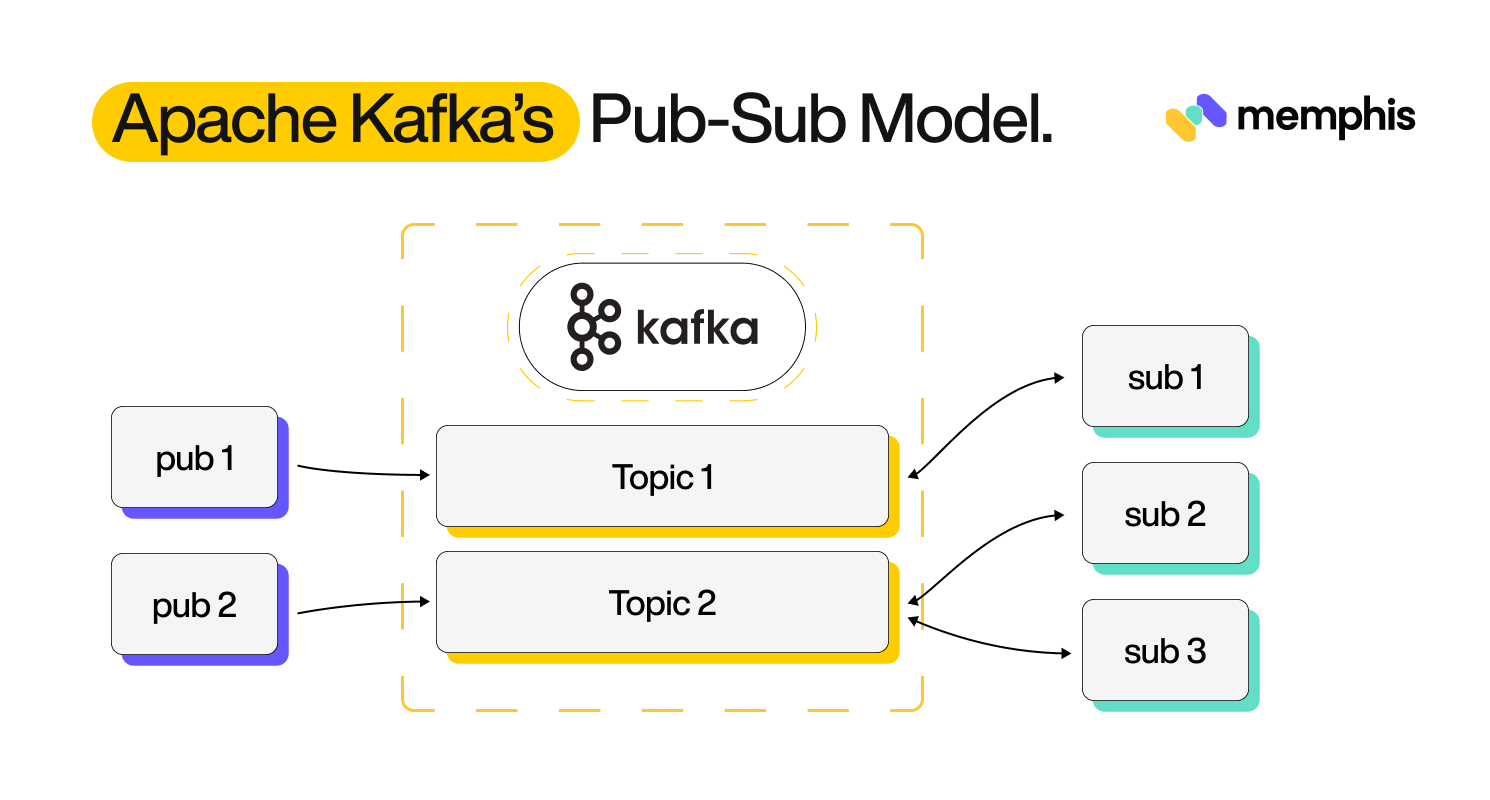
Kafka implements partitions across different brokers (Kafka servers/nodes) in a distributed manner. One topic (Kafka topic is where the data is stored and categorized. Data producers send data to topics, and data consumers read from topics) can have many partitions, and these partitions are stored in different brokers. The quorum system is the Kafka Raft (formerly ZooKeeper) which orchestrates the allocation of data to these partitions based on laid-down rules. Take, for example, a system for sending match updates as they happen. You could design the system with a topic called `match-updates` that has partitions for every team playing. These partitions can then be distributed across the message brokers in the system.
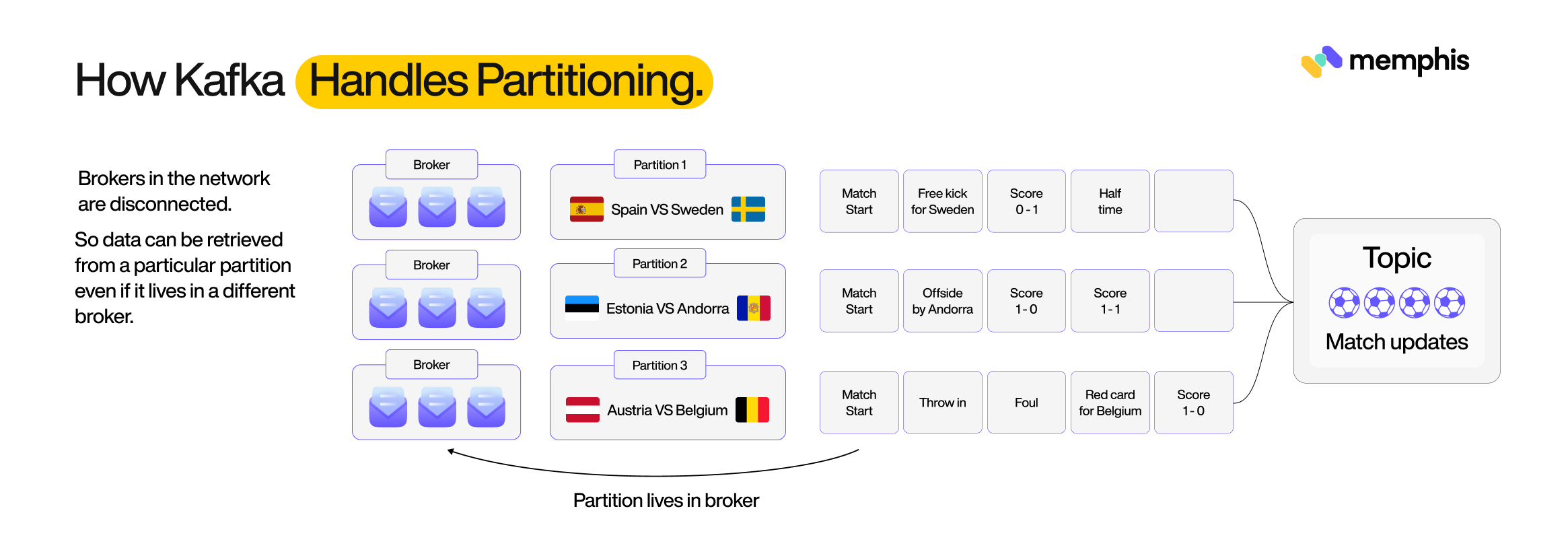
Main components of Kafka
Kafka has two main components:
- Brokers
- Coordinator service that allocates partitions – ZooKeeper/ KRaft
Formerly, Zookeeper was officially used for coordination, but ZooKeeper was deprecated(in release 3.4) and the recent versions now use KRaft.
Building applications with Apache Kafka
Apache Kafka is a distributed messaging platform that can be used to build a wide variety of applications and systems. One of the key advantages of using Kafka is its ability to handle high volumes of data and support real-time data processing, making it a great choice for big data and streaming applications. This section goes over the different types of applications that can be built using Apache Kafka.
- Log Aggregation: One of the most prevalent Kafka uses is in log aggregation. By collecting log data from multiple sources and sending it to a Kafka cluster, organizations can centralize their logs, making it easier to troubleshoot failures. Kafka is a popular choice for log aggregation because of its high-throughput, scalability, and durability. It achieves high-throughput by using a distributed architecture, where logs are produced to topics, and consumers can subscribe to topics to receive logs in real-time. Additionally, Kafka offers features such as compression and serialization, which can be used to optimize the storage and transmission of log data.
- Event-Driven Architecture: Another popular use case for Kafka is building event-driven architectures. In this type of architecture, instead of capturing the state of a system, events are continuously collected and processed in real-time. Kafka can be used to collect and transmit these events, allowing for real-time processing using tools such as Kafka Streams or Apache Spark. This type of architecture is particularly useful for applications that require real-time data processing, such as fraud detection and payment processing.
- Data Integration: Kafka can serve as a loading medium in an ELT (Extract Load Transform) pipeline. It could also stream ingested data to the services that perform data transformation. Kafka can work with stream processing applications like Kafka Streams and Apache Spark to perform data streaming within the data system.
- Streaming Applications: Kafka can also be used to build streaming applications, such as video streaming or IoT applications. For video streaming, Kafka can be used to ingest, distribute, and process video data in real time. For example, you can use Kafka to collect video data from cameras or other sources, process the data to extract metadata, and distribute the processed data to multiple consumers for analysis and reporting. For IoT applications, Kafka can be used to collect and process real-time data streams from IoT devices. For example, you can use Kafka to collect data from sensors, process the data to identify patterns or anomalies, and trigger actions based on specific conditions.
- Microservices: Kafka can be used to implement microservices-based architecture. By using a message queue, microservices can communicate with each other in a decoupled way, which makes the system more fault-tolerant and scalable.
Downsides of Kafka
Kafka, though powerful and widely used has some downsides that should be taken into consideration when deciding whether it is the right choice for a particular application or system. Some of the downsides of Kafka include:
- Complexity: Kafka is a highly configurable and flexible platform, but this can also make it quite complex to set up and manage. The platform requires a good understanding of distributed systems and the ability to configure and tune various parameters to ensure optimal performance.
- Scalability: While Kafka enables handling high volumes of data and supports real-time data processing, it can become a bottleneck when scaling to very large clusters. This is because the platform relies on a shared-nothing architecture, which can lead to contention and poor performance as the number of nodes increases.
- Limited Storage: Kafka stores data on disk, which makes it relatively fast when reading and writing data. However, the amount of data that can be stored is limited by the size of the disks. The default retention period for a topic is 7 days and can be increased, but if you need to store data for longer periods, you may need to consider other solutions.
- Latency: Kafka is designed to handle high-throughput data streams but can introduce some latency when processing data. This is because messages must be written to disk and replicated across multiple nodes before they can be consumed. This can be mitigated by increasing the number of nodes in the cluster and by optimizing the configuration of the system.
- Security: Kafka also provides some built-in security features, such as authentication and encryption, but it is not as robust as other messaging platforms when it comes to security. To make sure that you are using a robust security system, it is important to implement additional security measures such as network isolation and access control.
Memphis.dev as an alternative to Apache Kafka
Memphis is a next-generation alternative to Apache Kafka. It enables building modern queue-based applications that require large volumes of streamed and enriched data, modern protocols, zero ops, up to x9 faster development, up to x46 fewer costs, and significantly lower dev time for data-oriented developers and data engineers.
Memphis focuses on four pillars,
- Developer Experience – Rapid Development, Modularity, inline processing, Schema management.
- Observability – Reduces troubleshooting time to near zero.
- Performance and Efficiency – Provide good performance while maintaining efficient resource consumption.
- Stability – Queues and brokers play a critical part in the modern application’s structure and should be highly available and stable as possible.
One of the biggest advantages of Memphis.dev is its ability to handle high volumes of data with ease. Its unique architecture allows it to handle millions of messages per second with a very small footprint, making it a great choice for applications that require real-time data processing. One of the biggest advantages of Memphis.dev is its native ecosystem and DevEx, which removes most of the heavy lifting from the clients’ side like –
- Schema Enforcement and management
- No ZooKeeper, but Raft
- Kubernetes-native
- Data flow management
- Mirroring
- High-availability
- Auto Scaling
- Monitoring
- Messages retransmit
- Dead-letters
- Observability
If your use case requires event streaming and processing, you should give Memphis.dev a spin.
Message Broker vs Apache Kafka
Now we have discussed both message brokers and Kafka in detail. Simply put, Kafka is a message broker that is specifically optimized for high-throughput and real-time data streaming scenarios. Because of that Kafka can handle high-velocity data sources and deliver messages within milliseconds, making it suitable for real-time analytics and monitoring operations.
Traditional message brokers like RabbitMQ or ActiveMQ are more aligned with the imperative programming style. In imperative programming message brokers tell the system how to operate and how to accomplish tasks step by step. For example, how to receive messages, how to store them, how to send them to correct recipients, etc. On the contrary, Kafka aligns more with the reactive programming style. Reactive approaches focus more on explaining how the system responds to different situations while maintaining responsiveness, flexibility, and robustness. Rather than providing explicit instructions to the system for each message it receives, Kafka consumers subscribe to topics and respond to messages and events as they arrive.
So is Kafka a message broker? the answer is yes, but it’s more than a message broker with additional functionalities designed for distributed data storage, stream processing applications, and handling large throughput of data, acting more like a distributed streaming platform.
Conclusion
We’ve covered the special function of message brokers and Kafka in this article, which highlights the complexity of data processing. Through functions like queuing, routing, and transactional messaging, a message broker facilitates asynchronous communication and guarantees data integrity and delivery. By contrast, Apache Kafka goes one step further by putting in place a distributed architecture that enables real-time, high-throughput data streaming. Kafka is more than simply a message broker; it’s a full-featured streaming platform that meets the demands of the modern world for scalable, dependable, and fast data processing and distribution.
Kafka and message brokers are at a turning point in data-driven sectors. Kafka is increasingly necessary due to the growing demand for data-driven decision-making and real-time insights. However, as technology evolves, so do the expectations and complexities of the systems we build. Innovations like Memphis.dev are emerging, challenging traditional models by offering enhanced performance, efficiency, and developer experience.





