Report Memphis.dev Cloud Performance And Load Report
Data Engineering
Journey to Event Driven – Part 3: The Affinity Between Events, Streams and Serverless

 Contents
Contents
In this digital age, the way we build software has undergone a massive transformation. As software continues to advance and become more complex, developers are forced to think outside of the box when it comes to building apps that not only solve problems but also scale efficiently. New architectures and paradigms like Serverless are emerging as a result.
In Serverless architecture, there is no need for you to manage servers or containers. It completely abstracts away the process of launching and scaling your own virtual machines. Instead, you just upload your code once and let a third-party vendor take care of everything for you.
In this blog post, we will discuss the relationship between events, streams, and Serverless. Even though each of these concepts has unique benefits and use cases, there is an underlying affinity between them. They are all part of a larger trend towards cloud-first, dynamic applications and services. Each has its pros and cons, but together they make it easier to build more scalable and cost-efficient applications that can meet changing user demands. Let’s take a look at how these three technologies work well together.
Let’s discuss some basics first.
Serverless Architecture
Serverless is a cloud-computing execution model in which the cloud provider runs the server and dynamically allocates machine resources to run the code required to service events. Serverless is a model for building applications where the developers write code that runs in response to events and automatically manages the compute resources required to run that code. There is no need to provision or manage any servers.
In a Serverless architecture, you pay only for the ‘compute’ resources you use. There is no need to pay for idle capacity or for capacity that is used only infrequently. This can result in significant cost savings over traditional architectures.
The term Serverless is misleading, as these services still run on servers. The name refers to the fact that customers don’t have to manage or provision the underlying servers themselves. Serverless computing is a way to get all the benefits of the cloud without having to worry about managing servers. It’s a way to build applications faster and with less overhead.
Characteristics of Serverless Architecture
Let’s look at some of the characteristics of Serverless Architecture.
The serverless architecture enables you to build applications very quickly. Because there is no need to provision or manage servers, you can focus on writing code and deploying it into production without worrying about infrastructure.
Another trait of a Serverless architecture is that it is highly scalable. When an event occurs, the code is executed on demand and can scale up or down automatically to meet the needs of the event. This can be a big advantage over traditional architectures, which can often require manual scaling to meet changing demands.
Serverless architecture can also be more resilient than traditional architecture. If one function fails, the others can continue to run. This can help to ensure that your application remains available even if there are problems with one or more of the functions.
Serverless architecture can be more cost-effective than traditional architecture since you only pay for the resources you use (usually AWS Lambda) and don’t have to worry about maintaining any servers.
Serverless computing can also help you increase efficiency and focus on your core business. With Serverless computing, you don’t have to worry about patching, upgrading, or monitoring servers. All of that is taken care of by the cloud provider.
Disadvantages of Serverless
There are some disadvantages of Serverless architecture too.
One is that it can be more difficult to debug applications. This is because the code is spread out over many different functions, and each function is invoked independently. This can make it difficult to track down the source of a problem.
Another disadvantage is that a Serverless architecture can be more complex to set up and manage. This is because you need to configure and manage the various services that your application will use. This can be a challenge for developers who are not familiar with cloud-based architectures.
Despite these disadvantages, a Serverless architecture can be a great choice for many applications. It can provide cost savings, speed of development, and scalability. It is also more resilient than traditional architecture.
Components Of Serverless Applications
Serverless applications are composed of three components:
- An Event Source
- Function (Here we will be talking about AWS Lambda)
- Service
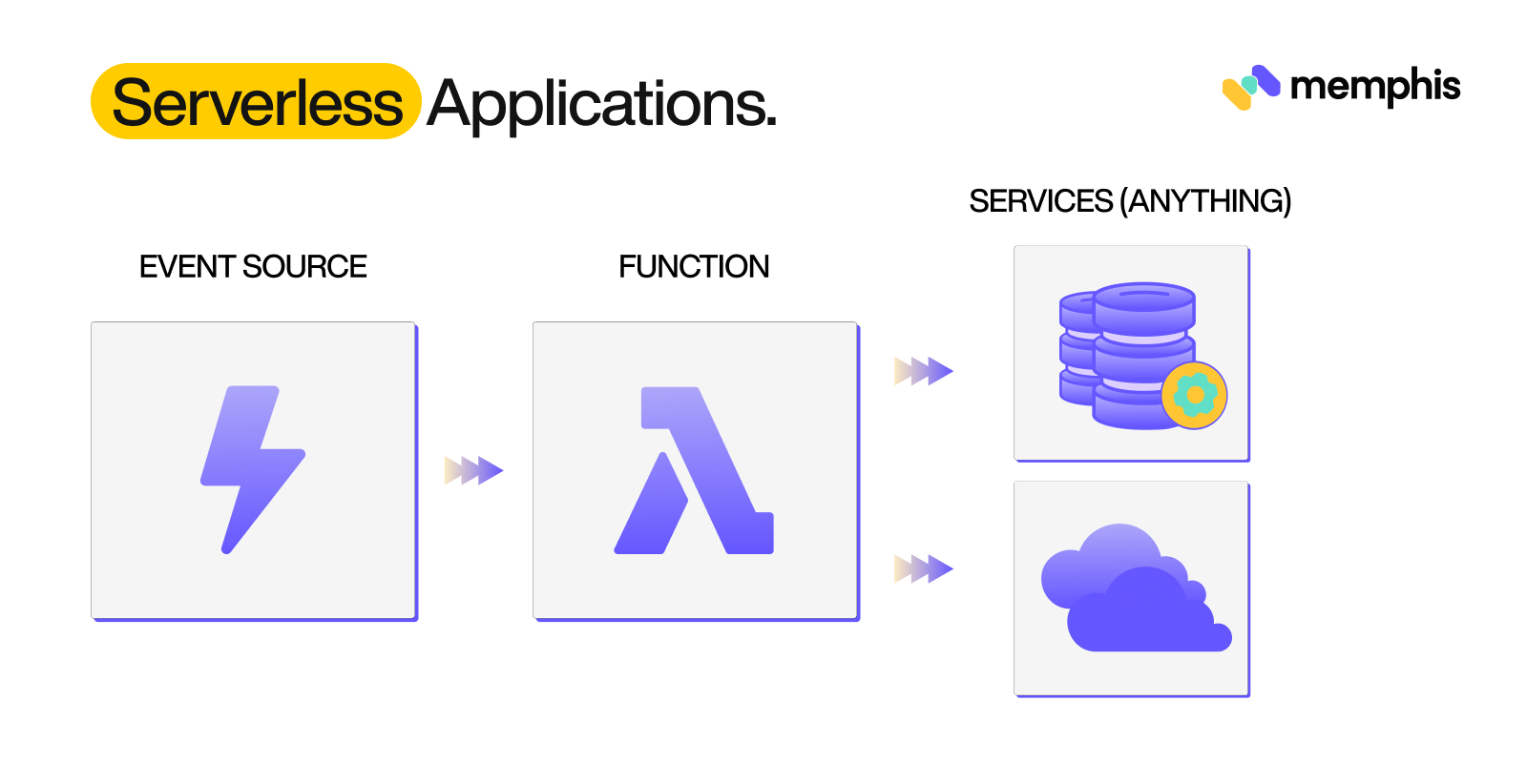
Event Source
An Event Source is an AWS service or developer-created application that produces events that trigger an AWS Lambda function. AWS Lambda uses Event Sources to process events. Event Sources can be either push-based or pull-based.
Push-based Event Sources send events to AWS Lambda as they occur. For example, Amazon S3 can be configured to send events to AWS Lambda when objects are created or deleted.
Pull-based Event Sources periodically invoke an AWS Lambda function to check for new events. For example, Amazon DynamoDB Streams can be configured to trigger an AWS Lambda function every time a stream record is modified.
Some of the event sources that Lambda supports are:
- Amazon S3
- Amazon DynamoDB
- Amazon Kinesis Data Streams
- Amazon Kinesis Data Firehose
- Amazon Simple Notification Service (SNS)
- Amazon Simple Queue Service (SQS)
- Amazon Managed Streaming for Apache Kafka
- Memphis
- RabbitMQ
Each Event Source has its own Event Structure.
For example, the Event Source Amazon S3 can produce different types of events, such as s3:ObjectCreated:* or s3:ObjectRemoved:*.
The Event Source Amazon DynamoDB can produce different types of events, such as DynamoDB:TableName:InsertItem , DynamoDB:TableName:UpdateItem , or DynamoDB:TableName:DeleteItem .
When configuring an Event Source, it is required to specify the AWS Lambda function that you want to invoke and the type of events that you want to process. You can also specify additional configuration settings, such as the batch size and processing interval.
Once an Event Source is configured, AWS Lambda will automatically invoke the Lambda function when events are generated by the Event Source. Then the Lambda function will process the event and perform any necessary actions.
Function
When it comes to Serverless applications, one of the key components is the function which is provided by the cloud provider as FaaS(Function-as-a-service).
A function is simply a piece of code that can be executed in response to an event. In AWS Lambda, functions are written in Node.js, Python, Java, or C#, etc. When a function is invoked, AWS Lambda passes the event data to the function code. The function code can then perform any desired actions, such as retrieving data from a database or calling an API.
Functions can be triggered by a variety of events, such as a new file being uploaded to Amazon S3, a new message being posted to an Amazon SQS queue, or an HTTP request being made to an Amazon API Gateway endpoint. It can be chained together to create complex workflows. For example, a function could be invoked when a file is uploaded to S3, which triggers another function to process the file and store the results in a database. When a function is invoked, it is assigned a Lambda function ARN. This ARN can be used to invoke the function from other AWS services, such as Amazon SNS or Amazon DynamoDB.
Service
Service is anything the function needs to do, and it could be updating a database, returning something to the client, or maybe talking to another API.
Introducing FaaS: A Subset of Serverless Computing
FaaS is a subset of Serverless computing and is responsible for the functions aspect of the Serverless architecture. It’s a way to run functions in an event-driven architecture. It lets you write short functional pieces of code that respond to events. For example, if a user sends a command to your app, the function might be triggered and make one database call to save data. You no longer need to worry about scaling – FaaS scales automatically!
FaaS can do anything from managing timers to logging activity or sending emails. The beauty of this system is that it frees up resources from having services running all the time just waiting for requests or input.
Plus, it makes monitoring much easier with constant uptime monitoring by providing metrics on CPU utilization, memory size, etc., which allows you to identify problems before they happen and fix them when they arise.
AWS Lambda Use Cases
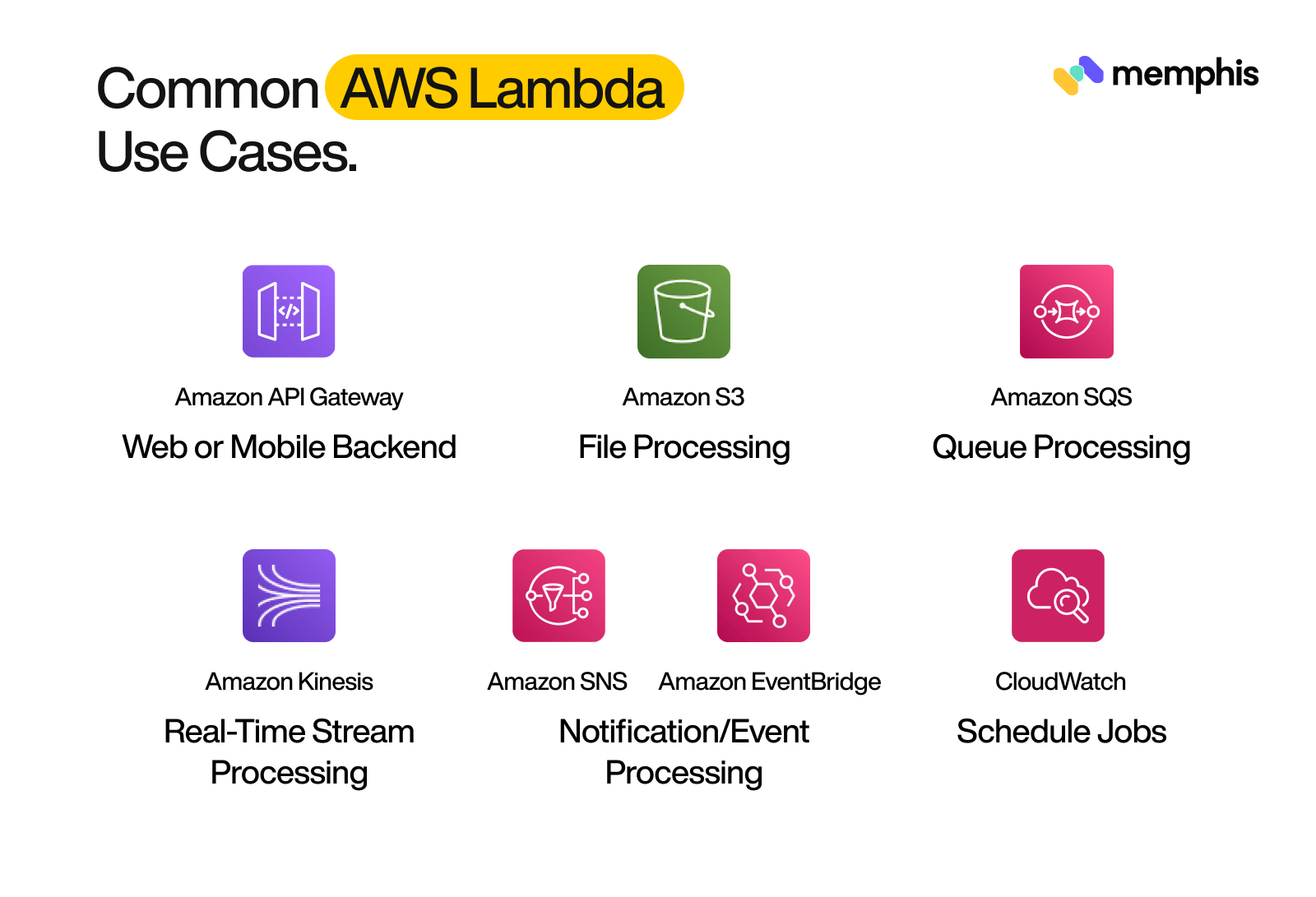
AWS Lambda is a perfect fit for many common use cases, such as:
- Back-end services: Lambda can be used to process events from Amazon S3, Amazon DynamoDB, Amazon Kinesis, and Amazon Cognito. For example, you can use Lambda to thumbnail images, transcode videos, index documents, process logs, validate content, and aggregate and filter data in real time.
- Mobile back-ends: Lambda can also be used to process messages from Memphis message broker. For example, you have a news app, you can use Lambda to send push notifications to every subscriber, subscribed to the Memphis station.
- File Processing: Lambda is also used to process files. For example, you have developed a video-streaming application and you want to upload a video which first requires compressing file size, and generating thumbnail. Assuming you have seperate services for each action, you can use a message broker like Memphis to inform that the file has been compressed and it will trigger the next action.
- Queue Processing: In some cases, Lambda is used to process messages from an Amazon SQS queue. For example, you can use Lambda to resize images or process orders.
- Real-time Stream Processing: Lambda can be used to process data from an Amazon Kinesis stream. For example, you can use Lambda to perform analytics on real-time data.
- Notification/Event Processing: Lambda also responds to events from Amazon SNS, Amazon CloudWatch, and other services. For example, you can use Lambda to send alerts or perform auto-scaling in response to Amazon CloudWatch alarms.
- Schedule Jobs: Lambda is used to run code on a schedule. For example, you can use Lambda to back up Amazon S3 buckets or DynamoDB tables.
Ways To Invoke Lambda Function
There are three execution models that AWS Lambda supports:
- Synchronous or Push-based Model
- Asynchronous or event-based model
- Stream or Poll-based Model
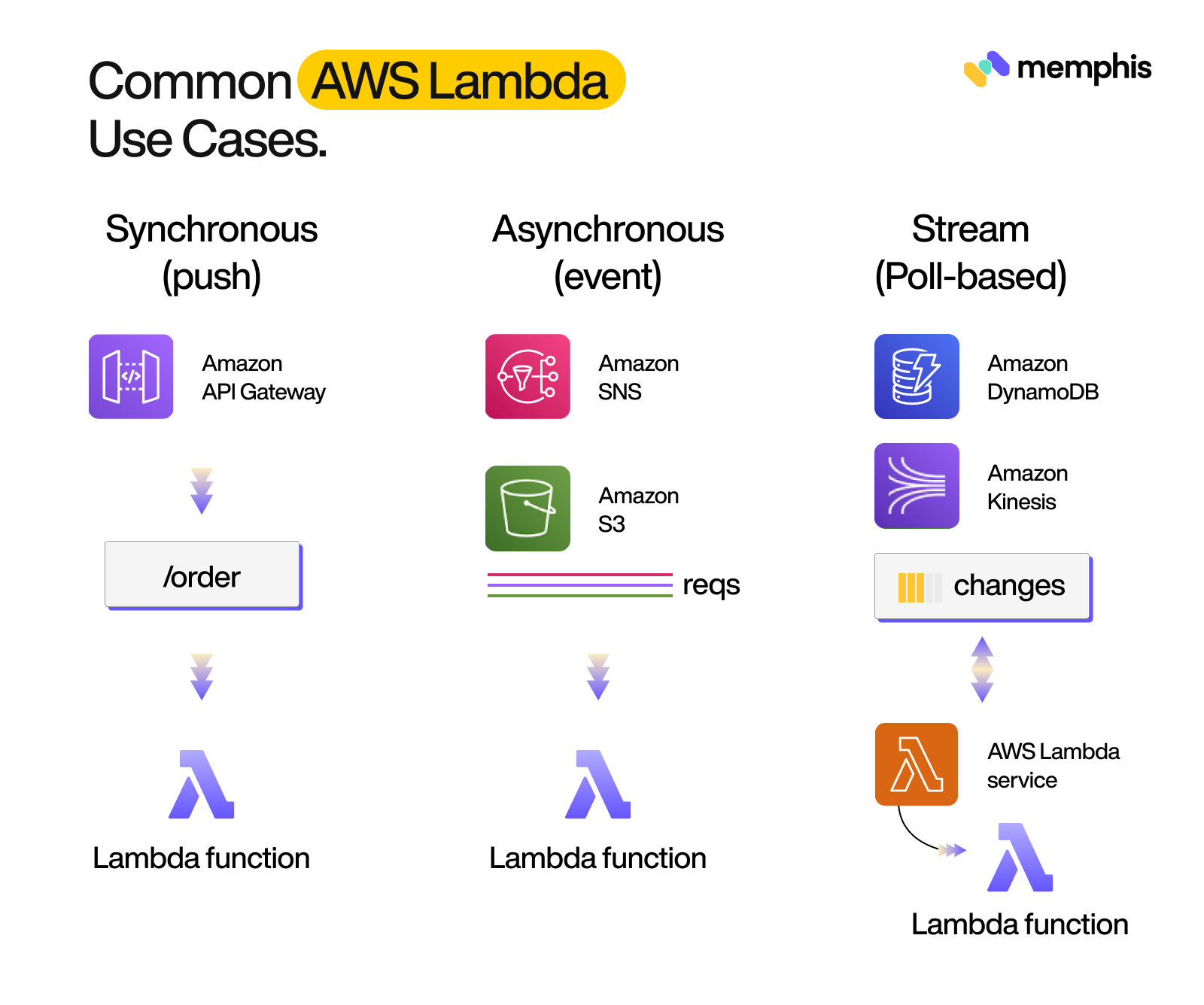
Synchronous or Push-based Model
Lambda synchronous invocation is a way of invoking a Lambda function where the caller expects a response. It is also known as Request-response Model.
When you invoke a Lambda function synchronously, Lambda sends the event to the function and waits for a response. The function processes the event and returns a response. If the function doesn’t return a response within the specified timeout, Lambda returns an error.
Lambda synchronous invocation is useful when you need to know the result of a function call, such as when you are processing a request that needs to be handled in a specific order. For example, if you are processing an order, you might need to invoke a Lambda function to calculate tax and another Lambda function to calculate shipping. In this case, you would use synchronous invocation so that the order is processed correctly.
Asynchronous or Event-based Model
The Asynchronous or Event-based Model is a way of programming where the flow of execution is determined by events. In this model, the code reacts to events as they happen.
These events can be generated by user interactions, system events, or changes to data stores. For example, a user might upload a file to Amazon S3, which can trigger a Lambda function to process the file and store information about it in Amazon DynamoDB.
Asynchronous invocation is a way of running Lambda functions in the background without having to wait for a response. This can be useful when you need to run multiple Lambdas at the same time or when you don’t need a response from a Lambda right away.
Stream or Poll-based Model
The Stream or Poll-based Model for invoking AWS Lambda is a way of invoking Lambda functions in response to events from Amazon Kinesis Streams or Amazon DynamoDB Streams. This model allows you to process data from these streams in near-real-time as the data becomes available.
For example, let’s say you have a stream of data from a DynamoDB table. You can set up your Lambda function to be invoked whenever there is a new item added to the table. The function can then process the item and perform any necessary actions.
Events And Streams: The Basics
In Serverless architecture, events are generated when a user interacts with the application, such as when a user clicks a button or uploads a file. These events are then processed by event-driven Lambda functions that perform the required actions, such as sending an email or updating a database record.
Streams are used to process event data in real time. For example, a stream can be used to process log data as it is generated or to process clickstream data to generate analytics in real time. Streams can process data from multiple sources, such as multiple Lambda functions, and can be processed by multiple Lambda functions.
Lambda Event Sources
Lambda supports multiple event sources. The following are some of the most popular event sources:
API Gateway
API Gateway can be used as an Event Source for AWS Lambda.
When API Gateway is configured as an event source for Lambda, it creates a REST API in front of the Lambda function that can be invoked from anywhere. This means that when a request is made to an API Gateway endpoint, the corresponding Lambda function will be invoked. This is a convenient and the most common way to trigger Lambda functions in response to events that occur in your API. For example, you could use this to automatically generate thumbnail images whenever a new image is uploaded to your API.
Amazon S3
Amazon Simple Storage Service (S3) can also publish events to AWS Lambda and invoke the Lambda function by passing the event data as a parameter. S3 can invoke a Lambda function when objects are created, deleted, or updated in a bucket. For example, you could configure a Lambda function to receive notifications when image files are added to an Amazon S3 bucket and then process the images and store them in a different bucket for further analysis.
Amazon DynamoDB
DynamoDB is an event-driven NoSQL database service. When DynamoDB makes a change to an item in a table, it can invoke a Lambda function. For example, if you have a table of user data and you want to trigger a Lambda function when a user is added or updated, you could use DynamoDB as the event source. The Lambda function could then perform any number of actions, such as sending an email to the user or updating another database.
Amazon Kinesis
Amazon Kinesis also works as an event source for lambda functions. This means that when certain events occur within Amazon Kinesis, Lambda will automatically invoke the associated function. For example, if you have a lambda function that is triggered when a new record is added to an Amazon Kinesis stream, then that function will be invoked every time a new record is added. This can be useful for processing data in real time as it arrives or for triggering other actions based on new data being added to a stream.
Amazon Kinesis can also invoke a Lambda function to perform additional processing on data records in a stream. For example, you could use Lambda to compress data records before storing them in Amazon S3 or invoke a Lambda function to perform real-time analytics on the records in an Amazon Kinesis stream.
Amazon SNS
Amazon SNS is a pub/sub messaging service that can be used to trigger Lambda functions. When a message is published to an Amazon SNS topic, all subscribers to that topic will receive the message, and any Lambda functions subscribed to the topic will be invoked. For example, you could use Amazon SNS to send notifications to all subscribers whenever a new product is added to your online store.
Amazon SNS messages can also trigger other AWS services such as SQS, SES, and SNS Mobile Push.
Amazon SQS
Amazon SQS is the perfect tool for decoupling and scaling microservices, distributed systems, and serverless applications.
It is one of the event sources that Lambda supports. The Lambda function is invoked when messages are added to an SQS queue to process the message. This is useful for processing data in real time as soon as it is available. For example, if you have a Lambda function that processes images, you can configure SQS to trigger the Lambda function when new images are added to an SQS queue.
Amazon SES
One of the most powerful event sources for Lambda is Amazon SES. Amazon SES invokes a lambda function when a certain event occurs in your Amazon SES account. Let’s say an email is received, which invokes a Lambda function to parse the email and save the data to a database.
Amazon EventBridge
EventBridge is a fully managed, powerful event routing service that allows you to connect applications running on any platform with data from different other services.
EventBridge uses a publish-subscribe model to route events from event sources to targets such as AWS Lambda functions, Amazon Kinesis streams, Amazon SNS topics, and built-in Amazon EC2 instances.
Amazon EventBridge invokes a Lambda function when an event is sent to a target that is configured to invoke that Lambda function. For example, you can configure an Amazon S3 bucket to send events to an EventBridge rule. The rule can have a Lambda function as a target, which EventBridge invokes when it detects an event in the bucket.
Amazon MSK
Amazon MSK is an event source for AWS Lambda. It invokes a Lambda function to perform specific actions when certain events occur within an Amazon MSK cluster.
Amazon MSK invokes a lambda function when a new event is detected in the stream. For example, if a new record is added to the stream, Amazon MSK will invoke the lambda function with the new record as an input.
When configuring an event source, you specify the name of the Lambda function to invoke and the event source mapping that describes how to process events from the event source.
Memphis
Handling too many data sources can be very complicated so, instead of using the above-listed sources, you can shift to a cloud-native message broker’ offered by Memphis.dev.
Let’s first put some light on what a message broker is.
A message broker is a piece of software that mediates communication among applications by translating messages from the sender’s application protocol to the receiver’s application protocol. It allows different applications to communicate with each other without the need for each application to have direct knowledge of the other. The message broker handles the details of the communication, making it possible for the applications to focus on their own functionality.
Message brokers can provide a variety of features, such as message transformation, routing, and message queuing. These features can be used to facilitate communication between applications that use different protocols or that are running on different platforms.
Memphis.dev is an open-source, dev-first, low-code, and real-time data streaming platform that provides a distributed message broker which can be used as an event producer to invoke the function. It is written in the Go programming language and is designed to be lightweight and easy to use. It allows for communication between a client and a server without the need for a persistent connection. The client can send messages to the server and the server can respond in real time. This makes it ideal for applications that need to be updated in real-time, such as chat applications, gaming applications, and so on.
Memphis primarily focuses on four pillars: Performance, Resiliency, Dev Experience, and Observability.
Memphis is a great choice for Asynchronous Task management, Real-time streaming pipelines, Data ingestion, Async communication between services on k8s, and Queuing.
RabbitMQ
RabbitMQ is also a message broker that allows clients to connect and exchange messages. It is written in Erlang and is available for a variety of platforms. It supports a variety of protocols and has a pluggable architecture that allows for a high degree of customization.
RabbitMQ is used in a variety of applications, including: Messaging applications, Distributed systems, Microservices, Event-driven architectures, Real-time data processing.
Ways to Compare Different Event Sources
When it comes to Lambda, one of the benefits is that it can be triggered by a variety of event sources. This can include everything from file uploads to S3 to API calls made to Amazon API Gateway. And because Lambda is a serverless platform, it can be a cost-effective option for many projects. But how do you know which event source is the best for your project? Let’s take a look at some of the key factors you should consider when comparing event sources for Lambda.
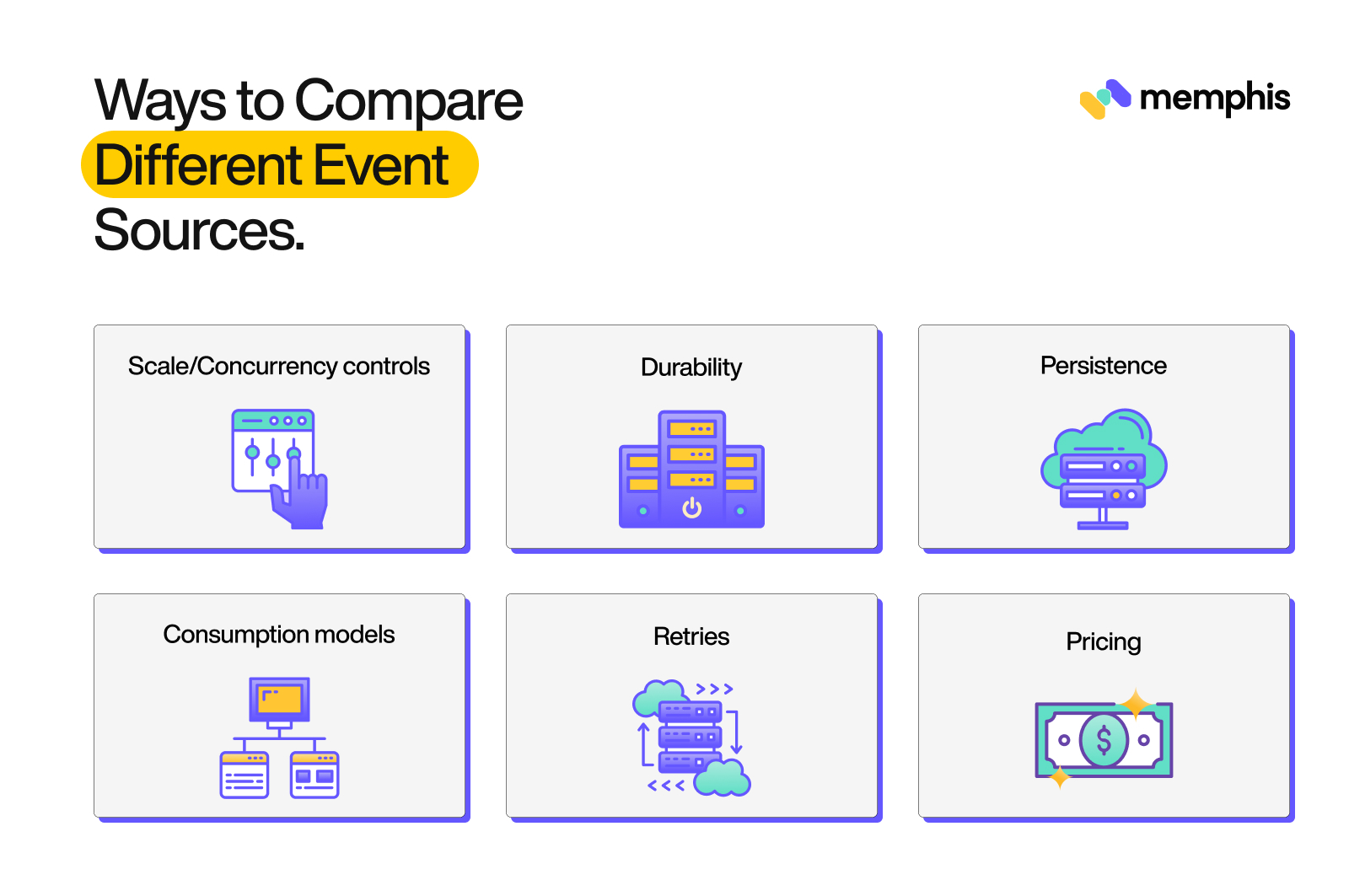
Scale and Concurrency Controls
One of the most important factors to consider is how well the event source can scale. After all, if your Lambda function is being triggered by an event source that can’t keep up with demand, it’s going to cause problems. You’ll also want to consider concurrency controls. This is especially important if you’re using Lambda in an environment where multiple users could be invoking the function at the same time.
Durability
An important factor to consider when choosing an event source is durability. Durability refers to how long events are stored by the event source before they are processed by Lambda. Some event sources, such as Amazon S3, can store events indefinitely. Other event sources, such as Amazon Kinesis Streams, only store events for a certain amount of time (24 hours by default).
This is especially important if you’re processing data that can’t be easily reproduced. For example, if you’re processing financial data, you’ll want to make sure that the event source is durable so that data isn’t lost if there’s a problem.
Persistence
Another factor to consider is persistence. Persistence refers to how long events are stored by Lambda after they are processed. Lambda can store events in an Amazon S3 bucket for up to 14 days. After that, events are automatically deleted.
Persistence becomes important if you need to reprocess data or if you want to keep a record of all data processing. For example, if you’re processing log data, you’ll want to make sure that the event source is persistent so that the data isn’t lost if the Lambda function crashes.
Consumption Models
There are two ways an event source can trigger a Lambda function: push or pull. With a push model, the event source sends events to Lambda as they occur. With a pull model, Lambda polls the event source regularly to check for new events.
When you’re comparing event sources, you’ll also want to consider the consumption model. This is important because it will affect the cost of using the event source. For example, if you’re only processing data when it’s uploaded to S3, you’ll only be charged for the data that’s actually processed. However, if you’re using an event source that invokes the Lambda function on a regular basis, you’ll be charged for each invocation.
Retries
Retry, or failure handling, is also a very important factor when choosing an event source, as it can have a significant impact on the response time of your Lambda function and its ability to handle high volumes of events.
This is important because it can affect the reliability of the event source. For example, if an event source only retries failed invocations a few times, the Lambda function may fail if there are a lot of failed invocations. So this factor should be kept in mind during the event source for AWS Lambda.
Pricing
The last but one of the most important factors to consider is the cost of maintaining an event source over time, as well as whether it’s free or paid in nature. Some event sources, such as Amazon SNS, are free to use. Others, such as Amazon Kinesis Streams, charge a monthly fee. So you need to understand how much overhead each service will incur on your app before choosing one over another.
Conclusion
This article gives a high-level overview of Serverless Architecture, FaaS, AWS Lambda, its common use cases, different Amazon event sources that Lambda supports, and what factors should be kept in mind while choosing the best event source for AWS Lambda.





